
پردازش تصویر چیست؟ تکنیک ها، انواع و کاربردها

- مقدمه ای بر معرفی پردازش تصویر
- پردازش تصویر چیست؟
- اهداف پردازش تصویر
- کاربردهای پردازش تصویر
- 6. تحلیل تصاویر ماهوارهای
- انواع تصاویر: ماشینها چگونه تصاویر را “میبینند”؟
- اهمیت پردازش تصویر در بیزینس
- مراحل پردازش تصویر
- 1. دریافت تصویر (Image Acquisition)
- 2. بهبود تصویر (Image Enhancement)
- 3. بازسازی تصویر (Image Restoration)
- 4. پردازش تصویر رنگی (Color Image Processing)
- 5. پردازش موجک و چندرزولوشنی (Wavelets and Multi-Resolution Processing)
- 6. فشرده سازی تصویر (Image Compression)
- 7. پردازش مورفولوژیکی (Morphological Processing)
- 8. تقسیم بندی تصویر (Image Segmentation)
- 9. نمایش و توصیف (Representation and Description)
- 10. تشخیص و شناسایی اشیاء (Object Detection and Recognition)
- 11. پایگاه دانش (Knowledge Base)
- تکنیکهای پردازش تصویر
- وظیفه 1: بهبود تصویر (Image Enhancement)
- وظیفه 2: بازسازی تصویر (Image Restoration)
- وظیفه 3: بخش بندی تصویر (Image Segmentation)
- وظیفه 4: تشخیص اشیاء (Object Detection)
- وظیفه 5: فشرده سازی تصویر (Image Compression)
- وظیفه 6: دستکاری تصویر (Image Manipulation)
- وظیفه 7: تولید تصویر (Image Generation)
- وظیفه 8: ترجمه تصویر به تصویر (Image-to-Image Translation)
چکیده مقاله: پردازش تصویر یک تکنیک بر اساس تقاضا است و نقش مهمی در این دوره در حال تکامل ایفا می کند. پردازش تصویر دیجیتال فرآیندی است که شامل تجزیه و تحلیل و دستکاری تصاویر به صورت دیجیتالی از طریق رایانه است تا آنها را برای تفسیر انسان و اطلاعات تصویر برای کارهایی مانند نگهداری ذخیره سازی، انتقال سریع و استخراج داده های تصویری آموزنده تر کند. این در حوزه های مختلفی مانند اتوماسیون، پزشکی، سنجش از دور و غیره استفاده می شود. در این مطلب به بررسی کامل آن می پردازیم با ما همراه باشید.
پردازش تصویر به فرآیند دستکاری تصاویر دیجیتال گفته میشود. در این فرآیند، تکنیکهای مختلفی از جمله بهبود تصویر، بازسازی و سایر موارد مورد استفاده قرار میگیرند. یادگیری عمیق تحولی بزرگ در دنیای بینایی کامپیوتر ایجاد کرده است. این توانایی به ماشینها این امکان را میدهد که دنیای اطراف خود را “ببینند” و تفسیر کنند. شبکههای عصبی کانولوشنی (CNNs) به طور خاص برای پردازش دادههای تصویری به شکلی کارآمدتر نسبت به شبکه های پرسپترون چندلایه (MLP) طراحی شدهاند. از آنجا که تصاویر دارای الگوهای پیوستهای در چندین پیکسل هستند، پردازش آنها به صورت پیکسل به پیکسل، مانند کاری که MLP ها انجام می دهند، ناکارآمد است. به همین دلیل، CNN ها که تصاویر را به صورت تکههای کوچک یا پنجرههایی پردازش میکنند، اکنون به گزینه استاندارد برای انجام وظایف پردازش تصویر تبدیل شدهاند.
نکات کلیدی
- عصر فناوری اطلاعات که در آن زندگی می کنیم، داده های بصری را به طور وسیعی در دسترس قرار داده است. با این حال، برای انتقال آنها از طریق اینترنت یا برای اهدافی مانند استخراج اطلاعات، مدل سازی پیشبینی و غیره، به پردازش زیادی نیاز است.
- پیشرفت فناوری یادگیری عمیق به ظهور مدلهای CNN انجامیده است که بهطور خاص برای پردازش تصاویر طراحی شدهاند. از آن زمان، مدلهای پیشرفتهتری توسعه یافتهاند که به وظایف خاصی در حوزه پردازش تصویر پاسخ میدهند. ما به برخی از مهمترین تکنیکها در پردازش تصویر و روشهای مبتنی بر یادگیری عمیق که به این مشکلات میپردازند، از جمله فشرده سازی و بهبود تصویر تا سنتز تصویر نگاه می کنیم.
- تحقیقات اخیر بر کاهش نیاز به برچسب های حقیقت زمینی برای وظایف پیچیدهای مانند تشخیص اشیاء، جداسازی معنایی و غیره با استفاده از مفاهیم مانند یادگیری نیمه نظارتی و یادگیری خود نظارتی متمرکز شدهاند که مدلها را برای کاربردهای عملی گستردهتر مناسبتر میکند.
مقدمه ای بر معرفی پردازش تصویر
پردازش تصویر یک حوزه وسیع است که شامل فرآیندهای مختلفی از جمله بهبود، استخراج ویژگی، ثبت، جداسازی، تطبیق الگو، طبقهبندی، ادغام، تحلیل مورفولوژی و اندازهگیریهای آماری میشود. از اینرو، پژوهشگران به مطالعه کاربردهای متنوع پردازش تصویر و الگوریتم های بهینه سازی علاقه مند هستند. بهطور کلی، ثبت تصویر یک فرآیند مهم در بسیاری از کاربردها است. این فرآیند به هم راستا کردن دو تصویر که به یک صحنه مشابه تعلق دارند، در یک سیستم مختصات مشترک برای شناسایی یک شیء مشخص، با مقایسه مقادیر پیکسل به پیکسل هر دو تصویر حسشده و مرجع اشاره دارد. این تصاویر هم راستا شده ممکن است از دستگاههای تصویربرداری مختلف یا در زمانهای متفاوتی گرفته شده باشند. علاوه بر این، از آنجا که محتوای ویدئویی به چندین فریم تصویر جدا می شود، در ثبت ویدئو، هر تصویر متحرک (تصویر هدف) با یک تصویر مرجع (ثابت) تطبیق داده می شود. معمولاً، تصویر مرجع ثابت نگه داشته می شود و بهعنوان مبنایی برای تصویر حس شده استفاده می شود.
ثبت توالی ویدئویی شامل بازیابی تغییرات فضایی و بازیابی هم راستایی زمانی بین دو ویدئو است. ویژگیها از هر فریم از دو توالی ویدئویی استخراج میشوند. پس از آن، ویژگیهای یک فریم در توالی اول با ویژگیهای مربوط به فریم در توالی دوم مقایسه می شوند.
در دهههای اخیر، تکنیکهای ثبت تصویر غیرسخت افزاری برای افزایش دقت ثبت گسترش یافتهاند. این روشها شامل معیارهای مشابهت (بر اساس شدت، نقاط مرجع، سطوح)، مدلهای تغییر شکل مختلف (مدلهای غیرسخت افزاری با استفاده از اسپلاين ها، مدلهای سخت/تبدیلی، موجکها، مدلهای متراکم/غیرپارامتریک) و قیدهای منظم و همچنین اضافه کردن قیدهای مختلف بر روی تغییرات است.
بهطور کلی، تصحیح حرکت مؤثر نیاز به ثبت تصویر غیرسختافزاری دارد که تطبیق جزئیات محلی بین دو تصویر را نسبت به ثبت سخت، انعطاف پذیرتر می سازد. B-splines میتوانند مدل تغییرات غیرسختافزاری را تطبیق دهند، جایی که شبکهای با اندازه پنجره ثابت تشکیل میشود تا به نقشهبرداری تصویر هدف بر اساس تصویر مرجع کمک کند. روشهای ثبت تصویر غیرسختافزاری بهطور گستردهای به دو کلاس تقسیم میشوند: تکنیکهای مبتنی بر شدت و تکنیکهای مبتنی بر ویژگی. تکنیکهای مبتنی بر ویژگی مدلهای دقیقی را بدون انتخاب دستی یا خودکار نقاط کنترل/ویژگیها ارائه می دهند. آنها از مدل بردار ویژگی برای تطبیق ویژگی های مرتبط بین تصاویر استفاده می کنند. بنابراین، فرآیند ثبت میتواند بهعنوان یک مشکل تطبیق ویژگی در نظر گرفته شود. برای تطبیق تصاویر، تکنیک های مبتنی بر ویژگی به تعداد نسبتاً کمی از نقاط ویژگی وابسته هستند.
در مقابل، تکنیکهای مبتنی بر شدت بهطور مستقیم با شدت تصویر سر و کار دارند و مشابهت شدت را اندازه گیری می کنند، و سپس تغییرات را تنظیم میکنند تا زمانی که اندازه گیری مشابهت به مقدار بهینه اش برسد. Thirion (1998) الگوریتم شیاطین را بهعنوان یک نماینده برای تکنیکهای مبتنی بر شدت معرفی کرد. این الگوریتم بر اساس معیار حفظ شدت بین تصاویر است که از مدل جریان نوری به دست آمده است. در الگوریتم شیاطین، هر پیکسل میتواند جابجایی خاص خود را داشته باشد. با این حال، در تصاویر واقعی، تطابق دقیق شدتها لزوماً به معنای ثبت خوب تصاویر زیرین نیست. بنابراین، تابع انرژی که در تکنیکهای مبتنی بر شدت بهینهسازی میشود، به شدت تحت تأثیر حداقل های محلی قرار میگیرد. شیاطین نمونهای از الگوریتم ثبت سیالی است که پارامترهای مختلفی مانند هسته هموارسازی سرعت و ثابت نویز آلفا دارد. بنابراین، این الگوریتم نیاز به الگوریتم های بهینه سازی برای دستیابی به مقادیر بهینه پارامترها دارد.
علاوه بر این، در جداسازی ویدئو، رابطه بین فریمهای دو توالی ویدئویی ناشناخته است. این رابطه می تواند با استفاده از تمام انتخاب های ممکن از جفت فریمها از دو توالی ویدئویی بهدست آید. این طرح جستجوی وسیع به نتیجه بهینه می انجامد، اما با هزینه محاسباتی بیشتری برای حل این بهینه سازی brute-force مواجه است.
در نتیجه، باید از الگوریتم های بهینه سازی برای جستجوی راهحلهای بهینه خاص با استفاده از یک تابع هدف/چند هدفه استفاده کرد. الگوریتمهای متاهوریستیک، مانند بهینهسازی ازدحام ذرات (PSO)، جستجوی جوجه تیغی (CS) و الگوریتم جستجوی آتشپرفس (FA)، رویکردهای سطح بالایی برای کاوش در فضاهای جستجو هستند.
پردازش تصویر چیست؟
پردازش تصویر دیجیتال به دستهای از روشها گفته میشود که با استفاده از الگوریتمهای کامپیوتری به دستکاری تصاویر دیجیتال می پردازند. این مرحله پیش پردازشی ضروری در بسیاری از کاربردها مانند تشخیص چهره، تشخیص اشیاء و فشرده سازی تصاویر است.
پردازش تصویر به منظور بهبود یک تصویر موجود یا استخراج اطلاعات مهم از آن انجام می شود. این امر در بسیاری از برنامههای مبتنی بر یادگیری عمیق و بینایی کامپیوتر اهمیت زیادی دارد، زیرا چنین پیش پردازشی میتواند به طور چشمگیری عملکرد یک مدل را بهبود بخشد. دستکاری تصاویر، مانند افزودن یا حذف اشیاء در تصاویر، نیز کاربرد دیگری است که به ویژه در صنعت سرگرمی به کار میرود.
در این مقاله، یک مسئله تقسیمبندی تصویر پزشکی مورد بررسی قرار گرفته است که نویسندگان از تکنیک پر کردن تصویر (inpainting) در مراحل پیش پردازش برای حذف نویزها و آثار ناخواسته از تصاویر درموسکوپی استفاده کردهاند. نمونههایی از این عملیات در زیر نشان داده شده است.

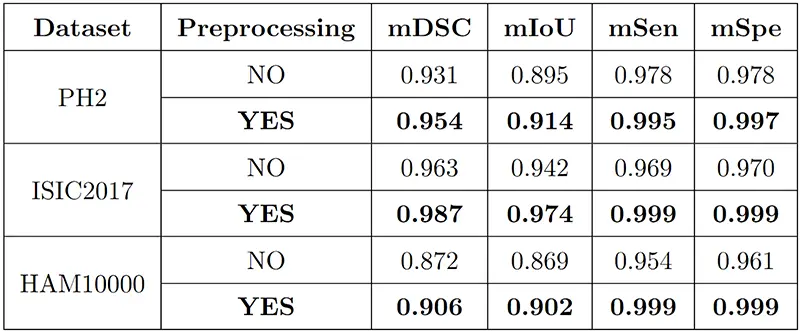
نویسندگان با استفاده از این روش ساده پیش پردازش، موفق به بهبود ۳ درصدی در عملکرد مدل شدند که این بهبود در برنامههای زیست پزشکی بسیار قابل توجه است، چرا که دقت تشخیص در سیستمهای هوش مصنوعی بسیار حائز اهمیت است. نتایج کمی به دست آمده با و بدون پیش پردازش برای مسئله تقسیم بندی ضایعات در سه مجموعه داده مختلف در زیر نشان داده شده است.
اهداف پردازش تصویر
بهبود وضوح تصویر: پردازش تصویر باعث افزایش وضوح تصاویری میشود که در حالت خام ممکن است قابل مشاهده نباشند. این شامل بهبود ویژگیهایی است که به دلیل کنتراست یا نویز پایین به وضوح دیده نمیشوند. تکنیکهایی مانند کشش کنتراست، تساوی هیستوگرام و فیلترینگ میتوانند جزئیات مهم را واضحتر کنند و در وظایفی مانند تصویربرداری پزشکی یا سنجش از دور کمک کنند.
ترمیم و افزایش وضوح تصویر: این هدف به بازگرداندن تصاویر خرابشده به کیفیت اصلی یا بهبود آنها برای استفاده بیشتر میپردازد. تکنیکهای ترمیم تصویر، مانند رفع تاری و کاهش نویز، برای حذف آثار ناشی از حرکت دوربین، نویز سنسور یا شرایط جوی استفاده میشوند. هدف این است که تصویری تصحیحشده تولید شود که بهدرستی صحنه اصلی را نمایش دهد.
استرداد تصویر: پردازش تصویر امکان استرداد تصاویر مهم از پایگاههای داده یا آرشیوهای بزرگ را فراهم میکند. تکنیکهایی مانند استرداد تصویر مبتنی بر محتوا (CBIR) از الگوریتمها برای شناسایی و استخراج تصاویر مرتبط بر اساس محتوای آنها استفاده میکنند. این موضوع در زمینههایی مانند تشخیص پزشکی بسیار مهم است، جایی که باید تصاویر خاصی از سوابق بیماران گسترده بازیابی شوند.
اندازهگیری و تحلیل: پردازش تصویر تسهیل اندازهگیری کمی اشیاء درون تصویر را فراهم میکند. این میتواند شامل محاسبه ابعاد، مساحت یا حجمها باشد که بهویژه در تحقیقات علمی و کاربردهای صنعتی مفید است. بهعنوان مثال، اندازهگیری اندازه سلولها در مطالعات بیولوژیکی یا ارزیابی ابعاد قطعات در مهندسی میتواند دادههای حیاتی برای تحلیل فراهم کند.
شناسایی و طبقهبندی اشیاء: یکی از اهداف اصلی پردازش تصویر توانایی شناسایی و تفکیک اشیاء خاص درون تصویر است. این شامل استفاده از الگوریتمها و تکنیکهایی مانند یادگیری ماشین، یادگیری عمیق و شناسایی الگوها برای شناسایی و طبقهبندی اشیاء است. کاربردها شامل سیستم های شناسایی چهره، خودروهای خودران که عابران پیاده را شناسایی می کنند و سیستم های صنعتی که محصولات را طبقه بندی میکنند، میشود.
کاربردهای پردازش تصویر
1. شناسایی چهره
شناسایی چهره از تکنیکهای پردازش تصویر برای شناسایی و تأیید هویت افراد بر اساس ویژگیهای چهره آنها استفاده میکند. این کاربرد در امنیت و دسترسی به دستگاهها، مانند گوشیهای هوشمند، و همچنین در دوربینهای مداربسته و نظارت بر امنیت عمومی استفاده میشود. همچنین در شبکههای اجتماعی برای برچسبگذاری خودکار کاربران و در سیستمهای تحلیل رفتار مشتریان در فروشگاهها کاربرد دارد.
2. سنسور اثر انگشت
تکنولوژی سنسور اثر انگشت به پردازش تصویر برای شناسایی الگوهای منحصر به فرد در اثر انگشتها تکیه دارد. این کاربرد در قفلهای بیومتریک، کارتهای شناسایی و دستگاههای موبایل برای تأیید هویت بهکار میرود. سیستمهای شناسایی اثر انگشت در محیطهای امنیتی نیز برای کنترل دسترسی به مناطق حساس استفاده میشوند.
3. شناسایی شماره پلاک خودرو
سیستمهای شناسایی شماره پلاک خودرو به پردازش تصویر برای خواندن و شناسایی پلاکها از خودروها وابستهاند. این تکنولوژی در دوربینهای نظارتی، کنترل ترافیک، و مدیریت عوارض جادهای کاربرد دارد. همچنین برای ردیابی خودروهای سرقتی یا شناسایی خودروهایی که قوانین را نقض میکنند، بهکار میرود.
4. شناسایی عنبیه
شناسایی عنبیه یک روش بیومتریک بسیار دقیق است که از پردازش تصویر برای تحلیل ویژگیهای منحصر به فرد در عنبیه فرد استفاده میکند. این تکنیک بهویژه در سیستمهای امنیتی با سطح بالا، مانند تأسیسات نظامی و دولت، و همچنین در فرودگاهها و مراکز کنترل مرزی کاربرد دارد.
5. تصویربرداری پزشکی
پردازش تصویر در تصویربرداری پزشکی برای تجزیه و تحلیل و بهبود کیفیت تصاویر پزشکی مانند MRI، CT و X-Ray استفاده میشود. این تکنیکها به پزشکان کمک میکنند تا جزئیات بیشتری را از تصاویر استخراج کنند و تشخیص دقیقتری انجام دهند. همچنین میتواند برای شناسایی تغییرات در وضعیت بیماری یا پیگیری روند درمان مؤثر باشد.
6. تحلیل تصاویر ماهوارهای
در علم جغرافیا و محیط زیست، پردازش تصویر به تحلیل تصاویر ماهوارهای برای بررسی تغییرات زمین، پایش منابع طبیعی، و ارزیابی تأثیرات محیطی کمک میکند. این اطلاعات می تواند برای مدیریت منابع طبیعی، پیش بینی بلایای طبیعی و برنامه ریزی شهری استفاده شود.
7. پردازش ویدئو
پردازش تصویر در ویدئو شامل تکنیکهایی برای شناسایی و پیگیری اشیاء متحرک، تحلیل رفتار، و تجزیه و تحلیل محتوا است. این کاربرد در نظارت، تحلیل ورزشی و ایجاد سیستمهای هوشمند ترافیک بسیار مهم است. تکنیکهای مانند شناسایی حرکت و تجزیه و تحلیل فریم به فریم برای استخراج اطلاعات مفید از ویدئوها استفاده میشوند.
8. خودکارسازی صنعتی
در خطوط تولید، پردازش تصویر برای بازرسی کیفیت، شناسایی عیوب و کنترل فرآیند استفاده می شود. این سیستم ها می توانند محصولات را با سرعت بالا بررسی کنند و خطاها را در مراحل تولید شناسایی کنند که باعث کاهش هزینهها و افزایش کیفیت می شود.
9. واقعیت افزوده و واقعیت مجازی
در تکنولوژیهای واقعیت افزوده (AR) و واقعیت مجازی (VR)، پردازش تصویر برای شناسایی و تعامل با دنیای واقعی به کار میرود. این تکنیکها به ایجاد تجربیات immersives کمک میکنند و در زمینههای بازی، آموزش و بازاریابی کاربردهای فراوانی دارند.
10. صنعت سرگرمی و هنری
در تولید فیلم و بازی های ویدیویی، پردازش تصویر برای ویرایش، ایجاد جلوه های ویژه و حتی طراحی شخصیت ها به کار میرود. تکنیکهای مانند انتقال سبک، تغییر پسزمینه و ویرایش رنگها به تولیدکنندگان اجازه میدهند تا تصاویر جذاب و واقعگرایانهتری ایجاد کنند.
انواع تصاویر: ماشینها چگونه تصاویر را “میبینند”؟
تصاویر دیجیتال توسط کامپیوتر به عنوان ماتریس های دو بعدی یا سه بعدی تفسیر می شوند که هر مقدار یا پیکسل در این ماتریس نمایانگر دامنه (شدت) پیکسل است. معمولاً ما با تصاویر ۸ بیتی سروکار داریم که در آن دامنه از ۰ تا ۲۵۵ متغیر است.
بنابراین، یک کامپیوتر تصاویر دیجیتال را به صورت یک تابع میبیند: I(x, y) یا I(x, y, z)، که در آن “I” شدت پیکسل و (x, y) یا (x, y, z) نمایانگر مختصات پیکسل در تصویر هستند (به ترتیب برای تصاویر دودویی/خاکستری یا RGB).

سیستم مختصات استفاده شده در تصاویر
کامپیوترها با انواع مختلفی از تصاویر بر اساس نمایش توابع آنها سروکار دارند. در ادامه به بررسی این انواع می پردازیم:
1- تصویر دودویی
تصاویری که تنها دو مقدار منحصر به فرد از شدت پیکسل دارند – ۰ (که نشاندهنده رنگ سیاه است) و ۱ (که نشاندهنده رنگ سفید است) به عنوان تصاویر دودویی شناخته میشوند. این تصاویر معمولاً برای برجسته کردن بخشی از یک تصویر رنگی به کار میروند. به عنوان مثال، معمولاً در تقسیمبندی تصویر استفاده میشوند.

2- تصویر خاکستری
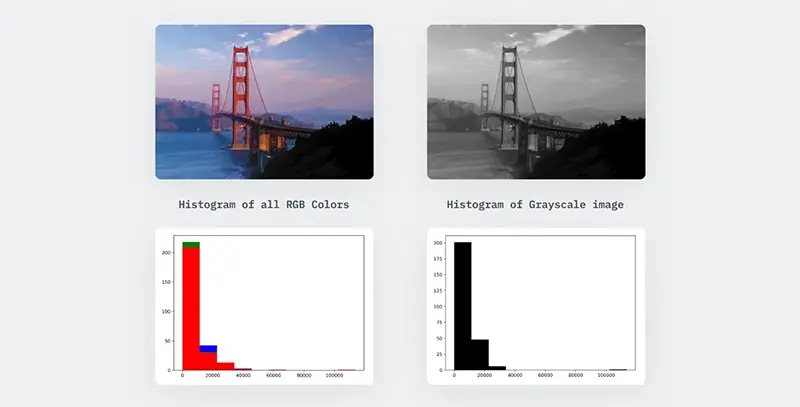
تصاویر خاکستری یا ۸ بیتی از ۲۵۶ رنگ منحصر به فرد تشکیل شدهاند، که شدت پیکسل ۰ نشاندهنده رنگ سیاه و شدت پیکسل ۲۵۵ نشاندهنده رنگ سفید است. سایر ۲۵۴ مقدار بینابینی، سایههای مختلفی از رنگ خاکستری هستند.
نمونهای از یک تصویر RGB که به نسخه خاکستری خود تبدیل شده است در زیر نشان داده شده است. توجه کنید که شکل هیستوگرام برای تصاویر RGB و خاکستری مشابه باقی میماند.
3- تصویر رنگی RGB
تصاویری که ما در دنیای مدرن با آنها سروکار داریم، تصاویر RGB یا رنگی هستند که به صورت ماتریسهای ۱۶ بیتی برای کامپیوترها نمایش داده میشوند. یعنی برای هر پیکسل ۶۵,۵۳۶ رنگ مختلف ممکن است. “RGB” نمایانگر کانالهای قرمز، سبز و آبی در تصویر است.
تا به اینجا، تصاویر تنها یک کانال داشتند. یعنی دو مختصات میتوانستند مکان هر مقدار از ماتریس را تعریف کنند. اکنون، سه ماتریس هماندازه (که به آنها کانال گفته میشود) داریم که هر کدام دارای مقادیری بین ۰ تا ۲۵۵ هستند و روی هم قرار میگیرند. بنابراین، برای تعیین مقدار یک عنصر ماتریس، به سه مختصات نیاز داریم.
یک پیکسل در تصویر RGB هنگامی که مقدار آن (۰، ۰، ۰) باشد سیاه و هنگامی که مقدار آن (۲۵۵، ۲۵۵، ۲۵۵) باشد سفید است. هر ترکیبی از اعداد بین این مقادیر، رنگهای مختلفی را ایجاد میکند. برای مثال، (۲۵۵، ۰، ۰) رنگ قرمز است (زیرا تنها کانال قرمز فعال است). به همین ترتیب، (۰، ۲۵۵، ۰) سبز و (۰، ۰، ۲۵۵) آبی است.
نمونهای از یک تصویر RGB که به کانالهای قرمز، سبز و آبی خود تفکیک شده است در زیر نشان داده شده است. توجه کنید که شکل هیستوگرام هر یک از کانالها متفاوت است.
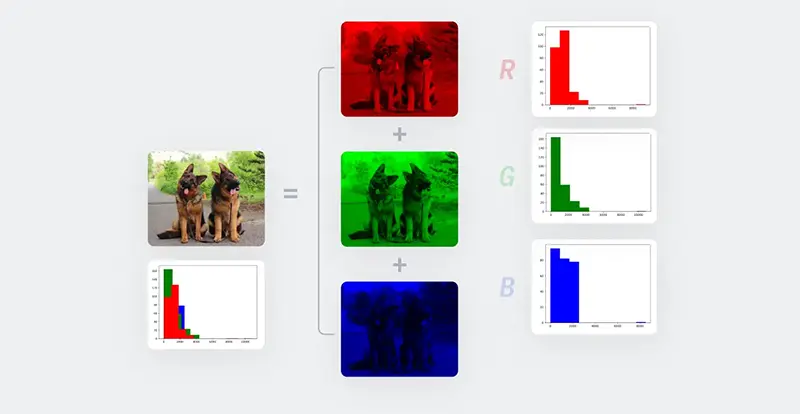
4- تصویر RGBA
تصاویر RGBA همان تصاویر رنگی RGB هستند که یک کانال اضافی به نام “آلفا” دارند که میزان شفافیت یا کدری تصویر RGB را نشان می دهد. شفافیت (Opacity) میتواند از 0% تا 100% متغیر باشد و اساساً نشان دهنده خاصیت “دیدن از میان” تصویر است.
در فیزیک، شفافیت نشان دهنده میزان نوری است که از یک جسم عبور میکند. به عنوان مثال، کاغذ سلفون کاملاً شفاف است (100% شفافیت)، شیشه مات نیمه شفاف و چوب کاملاً مات است. کانال آلفا در تصاویر RGBA سعی دارد این خاصیت را شبیه سازی کند. یک نمونه از این تصاویر در زیر نشان داده شده است.

اهمیت پردازش تصویر در بیزینس
پردازش تصویر به عنوان یک روش برای تغییر و بهبود تصاویر تعریف میشود، که با تغییر پارامترهایی مانند رنگ، روشنایی یا کنتراست انجام میشود. این تغییرات میتوانند بهصورت دستی یا با استفاده از الگوریتمهای کامپیوتری انجام شوند. پردازش تصویر در پروژههای صنعتی، مانند بازرسی صنعتی و تصویربرداری ماهوارهای، بسیار مفید است زیرا به تحلیل دقیق و آسان تصاویر کمک میکند.
بازرسی صنعتی
این حوزه بخشی از اتوماسیون کارخانه است که در آن فرآیندهای صنعتی با استفاده از رباتیک خودکار میشوند. یکی از فرآیندهایی که به پردازش تصویر نیاز دارد، بازرسی صنعتی است. بهعنوان مثال، در حین مونتاژ قطعات الکترونیکی بر روی یک بورد مدار، ممکن است نقصهایی مانند پایههای خم شده یا خشها به وجود آید که کیفیت محصول را تحت تأثیر قرار میدهد و منجر به هدر رفتن قطعات غیرقابل استفاده میشود. با استفاده از پردازش تصویر، میتوان این نقصها را شناسایی و پیش از نهایی شدن محصول تعمیر کرد.
بازرسی صنعتی با پردازش تصویر به بهبود کیفیت محصولات و کاهش هدررفت کمک میکند. با شناسایی عیوب در مراحل اولیه تولید، میتوان از تولید محصولات معیوب جلوگیری کرد.
تصویربرداری ماهوارهای
تصویربرداری ماهوارهای برای اهداف کشاورزی، مانند شناسایی مناطق مستعد خشکسالی، مدیریت الگوهای کشت و یافتن مناطق جدید برای کشاورزی، بسیار ضروری است. پردازش تصویر به تحلیل تصاویر ماهوارهای کمک میکند تا ناهنجاریهایی مانند کمبود آب یا توزیع نابرابر محصولات میان کشاورزان شناسایی شود. بسته نرمافزاری «EVI» که توسط ناسا استفاده میشود، تغییرات در پوشش گیاهی سطح زمین را که ناشی از عوامل طبیعی مانند طوفان و آتش سوزی جنگلها است، شناسایی می کند و به بهبود استراتژی های برنامه ریزی کشاورزی کمک میکند.
بینایی کامپیوتر
این حوزه از پردازش تصویر به تحلیل دادههای ویدیویی برای درک محتوای نهفته آن میپردازد، مانند شناسایی حرکات انسانی و حالات چهره. بینایی کامپیوتر در تصویربرداری پزشکی مانند MRI و CT Scan برای تشخیص بیماریها استفاده میشود و به پزشکان کمک میکند تا بیماریها را قبل از تشخیص سنتی شناسایی کنند. همچنین پردازش تصویر نقش مهمی در ناوبری رباتها دارد و با ارائه نشانه های بصری به این رباتها با استفاده از الگوریتمهای کامپیوتری، به آنها کمک میکند. ویژگی «Face ID» در گوشی آیفون X از الگوریتم «Face ID» استفاده میکند که چهره کاربر را اسکن کرده و با تطابق چشمان یا چهره با رکوردهای ذخیرهشده، گوشی را قفلگشایی میکند.
در زمینه پزشکی، پردازش تصویر در تکنیکهایی مانند MRI، CT Scan و سونوگرافی به پزشکان کمک میکند تا بیماریها را در مراحل اولیه شناسایی کنند. بستههای نرمافزاری مانند «EVI» و «Tomsk-903» به شناسایی عوامل بیماریزا و تشخیص سلولهای سرطانی یا خونریزیهای مغزی کمک می کنند.
مراحل پردازش تصویر
مراحل پردازش تصویر دیجیتال شامل مجموعهای از عملیات است که هر کدام وظیفهای خاص دارند تا تصویر را به شکلی که برای تحلیل، استفاده یا نمایش بهتر باشد، آماده کنند. در ادامه، توضیحات مفصلتری از هر مرحله ارائه میشود:
1. دریافت تصویر (Image Acquisition)
در این مرحله، تصویر به وسیله یک دوربین یا حسگر دیجیتال گرفته میشود. اگر دوربین آنالوگ باشد، باید از یک مبدل آنالوگ به دیجیتال (ADC) برای تبدیل سیگنالهای آنالوگ به دادههای دیجیتال استفاده کرد. نتیجه نهایی یک تصویر دیجیتال است که میتواند شامل مقادیر پیکسلی باشد. این مرحله معمولاً اولین گام در پردازش تصویر است و اساساً نقطه شروع کل فرایند محسوب میشود. تصاویر میتوانند به صورت تک فریمی یا چند فریمی (ویدیو) به دست آیند.
2. بهبود تصویر (Image Enhancement)
هدف این مرحله بهبود کیفیت تصویر است به گونهای که برای پردازشهای بعدی مناسبتر شود یا جزئیات پنهان آن آشکار گردد. بهبود تصویر معمولاً وابسته به نیازهای کاربر است و ماهیتی ذهنی دارد، یعنی یک تکنیک برای یک برنامه ممکن است مناسب باشد، اما برای برنامه دیگر مناسب نباشد. تکنیک های رایج شامل:
- تنظیم روشنایی و کنتراست: افزایش یا کاهش کنتراست تصویر برای مشخصتر شدن جزئیات.
- فیلترگذاری: برای حذف نویزها و ناهنجاریهای ناخواسته.
- تقویت لبهها: برجسته سازی لبههای تصویر برای بهبود دیداری ساختارها.
3. بازسازی تصویر (Image Restoration)
بازسازی تصویر بر پایه مدلهای ریاضی یا احتمالاتی انجام میشود و هدف آن بازیابی ظاهر اصلی تصویر است. این عملیات بیشتر به صورت عینی و هدفمند صورت میگیرد. مثلاً اگر تصویری به دلیل شرایط محیطی دچار نویز یا تاری شده باشد، بازسازی تصویر تلاش میکند تا این اثرات ناخواسته را حذف کند. تکنیکهای رایج شامل:
- حذف نویز: استفاده از فیلترهای مختلف مانند فیلترهای میانگین یا میانه برای حذف نویزهای تصادفی.
- کاهش تاری: حذف یا کاهش اثرات ناشی از حرکت یا لرزش دوربین.
4. پردازش تصویر رنگی (Color Image Processing)
این مرحله به پردازش تصاویر رنگی میپردازد. برای مثال، تصحیح رنگ، تغییر فضای رنگ یا مدلسازی رنگ در تصاویر انجام میشود. از آنجا که تصاویر رنگی معمولاً در سه کانال (قرمز، سبز و آبی) ثبت میشوند، پردازش هر کانال به صورت جداگانه یا ترکیبی از آنها انجام میشود. همچنین، تکنیکهایی برای تنظیم تراز سفیدی (white balance) یا تصحیح اشباع رنگ (color saturation) در این مرحله انجام میگیرد.
5. پردازش موجک و چندرزولوشنی (Wavelets and Multi-Resolution Processing)
این مرحله از موجکها به عنوان ابزارهای اصلی برای نمایش تصاویر در درجات مختلف وضوح استفاده میکند. موجکها امکان تقسیم تصویر به زیر بخشهایی با درجات مختلفی از جزئیات را فراهم میکنند. این تکنیک به ویژه برای فشردهسازی تصاویر و نمایشهای هرمی (pyramidal representations) به کار میرود. در فشرده سازی، تصاویر به بخشهای کوچکتر تقسیم میشوند و جزئیات کمتر مهم در سطوح پایینتر حذف میشوند.
6. فشرده سازی تصویر (Image Compression)
فشرده سازی تصویر به منظور کاهش اندازه فایل تصویری انجام میشود، به طوری که بتوان آن را سریعتر ارسال کرد یا در فضای ذخیرهسازی کمتری نگهداری کرد. این امر برای کاربردهایی مانند نمایش تصاویر در وب یا ذخیرهسازی انبوه تصاویر بسیار اهمیت دارد. فشردهسازی تصاویر به دو روش کلی انجام میشود:
- فشرده سازی با اتلاف: بخشی از اطلاعات تصویر حذف میشود که باعث کاهش کیفیت میشود اما اندازه فایل به طور قابل توجهی کاهش مییابد. نمونهای از این نوع فشرده سازی، فرمت JPEG است.
- فشرده سازی بدون اتلاف: هیچ بخشی از اطلاعات تصویر از بین نمیرود، اما اندازه فایل کمتر کاهش مییابد. نمونهای از این نوع، فرمت PNG است.
7. پردازش مورفولوژیکی (Morphological Processing)
پردازش مورفولوژیکی شامل مجموعهای از عملیات است که با شکلهای هندسی در تصویر سروکار دارد. این تکنیکها بیشتر در پردازش تصاویر دودویی (binary images) به کار میروند. عملیات رایج مورفولوژیکی شامل:
- خوردگی (Erosion): لبههای اشیاء در تصویر کاهش مییابند.
- گسترش (Dilation): لبههای اشیاء افزایش مییابند.
- باز کردن (Opening) و بستن (Closing): ترکیبی از خوردگی و گسترش برای حذف نویزها یا صاف کردن لبهها. این تکنیکها برای استخراج اطلاعاتی از شکلها و اشیاء موجود در تصویر به کار میروند و معمولاً برای شناسایی اشیاء یا آمادهسازی برای مراحل بعدی پردازش استفاده میشوند.
8. تقسیم بندی تصویر (Image Segmentation)
تقسیمبندی تصویر به معنی تقسیم یک تصویر به بخشهای مختلف و مجزا است. هدف اصلی از تقسیمبندی، سادهسازی یا تغییر نمایش تصویر به نحوی است که تحلیل و پردازش آن آسانتر شود. در این مرحله، اشیاء یا نواحی مهم تصویر از سایر بخشهای تصویر جدا میشوند تا روی آنها تمرکز شود. تقسیمبندی به صورت خودکار یا نیمهخودکار میتواند انجام شود. تکنیکهای تقسیمبندی شامل:
- آستانه گذاری (Thresholding): جدا کردن اشیاء بر اساس سطح شدت روشنایی.
- تقسیم بندی مبتنی بر ناحیه (Region-based Segmentation): گروهبندی پیکسلهای مجاور با ویژگیهای مشابه.
- روشهای مبتنی بر کانتور (Contour-based methods): پیدا کردن مرزهای اشیاء در تصویر.
9. نمایش و توصیف (Representation and Description)
پس از تقسیمبندی تصویر، نیاز است تا نواحی یا اشیاء جدا شده به نحوی نمایش داده شوند. در این مرحله، تصمیمگیری میشود که آیا ناحیه تقسیمبندی شده باید به صورت یک مرز (boundary) یا یک ناحیه کامل (region) نمایش داده شود. همچنین، ویژگی های اصلی ناحیه یا شیء استخراج میشود تا اطلاعات کمی در مورد آن ارائه شود. این ویژگی ها میتوانند شامل مواردی مانند شکل، اندازه، یا بافت شیء باشند که برای شناسایی یا دستهبندی آن به کار می روند.
10. تشخیص و شناسایی اشیاء (Object Detection and Recognition)
پس از نمایش و توصیف اشیاء، سیستمهای خودکار باید این اشیاء را شناسایی کنند و به آنها برچسبی اختصاص دهند. به عنوان مثال، یک شیء ممکن است به عنوان “خودرو” یا “شخص” شناسایی شود. در این مرحله، از تکنیکهای یادگیری ماشین یا یادگیری عمیق برای شناسایی و دستهبندی اشیاء استفاده میشود. تشخیص اشیاء ممکن است به صورت محلی (در یک بخش خاص از تصویر) یا به صورت کلی (در کل تصویر) انجام شود.
11. پایگاه دانش (Knowledge Base)
پایگاه دانش به معنای ذخیرهسازی اطلاعات مفید و مرتبط با تصاویر است که میتواند به بهبود دقت و کارایی پردازش تصویر کمک کند. این دانش ممکن است شامل اطلاعاتی مانند مختصات اشیاء در تصویر، برچسبهای اشیاء تشخیص داده شده، یا حتی ویژگیهای استخراج شده از تصاویر باشد. این اطلاعات میتوانند در فرایندهای بعدی پردازش یا تصمیمگیری استفاده شوند.
تکنیکهای پردازش تصویر
پردازش تصویر میتواند برای بهبود کیفیت تصویر، حذف اشیاء ناخواسته از تصویر یا حتی ایجاد تصاویر جدید از ابتدا استفاده شود. برای مثال، از پردازش تصویر میتوان برای حذف پسزمینه از تصویری که از یک شخص گرفته شده است استفاده کرد و تنها سوژه در پیشزمینه باقی بماند.
پردازش تصویر یک حوزه وسیع و پیچیده است که شامل بسیاری از الگوریتمها و تکنیکهای مختلف میشود که برای دستیابی به نتایج مختلف به کار میروند. در این بخش، ما روی برخی از رایجترین وظایف پردازش تصویر و نحوه انجام آنها تمرکز خواهیم کرد.
وظیفه 1: بهبود تصویر (Image Enhancement)
یکی از رایجترین وظایف در پردازش تصویر، بهبود تصویر یا بهبود کیفیت یک تصویر است. این تکنیک کاربردهای بسیار مهمی در وظایف بینایی کامپیوتری، سنجش از دور، و نظارت دارد. یکی از رویکردهای معمول، تنظیم کنتراست و روشنایی تصویر است.
کنتراست تفاوت در روشنایی بین روشنترین و تاریکترین نواحی یک تصویر است. با افزایش کنتراست، روشنایی کلی تصویر میتواند افزایش یابد و باعث شود تصویر بهتر دیده شود. روشنایی نیز میزان کلی روشنایی یا تاریکی تصویر را نشان میدهد. با افزایش روشنایی، تصویر میتواند روشنتر شده و بهتر دیده شود. تنظیم هر دو پارامتر کنتراست و روشنایی به صورت خودکار توسط بیشتر نرم افزارهای ویرایش تصویر انجام میشود یا میتوان آنها را به صورت دستی تنظیم کرد.

با این حال، تنظیم کنتراست و روشنایی تنها عملیاتهای ابتدایی برای بهبود تصویر هستند. گاهی اوقات تصویری که کنتراست و روشنایی آن بهدرستی تنظیم شده است، در هنگام بزرگنمایی ممکن است تار شود؛ این امر به دلیل تراکم پیکسلی پایینتر در هر اینچ (چگالی پیکسل) رخ میدهد. برای حل این مشکل، از مفهومی نسبتاً جدید و بسیار پیشرفته به نام رزولوشنسازی فوقالعاده (Super-Resolution) استفاده میشود، که در آن یک تصویر با وضوح بالا از نسخههای کموضوحتر آن به دست میآید. تکنیکهای یادگیری عمیق به طور گستردهای برای دستیابی به این هدف به کار میروند.

به عنوان مثال، یکی از اولین نمونههای استفاده از یادگیری عمیق برای حل مشکل رزولوشن سازی فوقالعاده، مدل SRCNN است. در این مدل، ابتدا تصویری با وضوح پایین بهصورت سنتی با استفاده از درونیابی بیکوبیک (Bicubic Interpolation) بزرگنمایی میشود و سپس به عنوان ورودی به یک مدل CNN داده میشود. نگاشت غیرخطی (Non-linear Mapping) در شبکه CNN پچ های همپوشانی شدهای از تصویر ورودی را استخراج میکند و یک لایه کانولوشنی روی پچهای استخراجشده به کار گرفته میشود تا تصویر بازسازی شده با وضوح بالا را به دست آورد. چارچوب این مدل به صورت بصری در تصویر زیر نشان داده شده است.
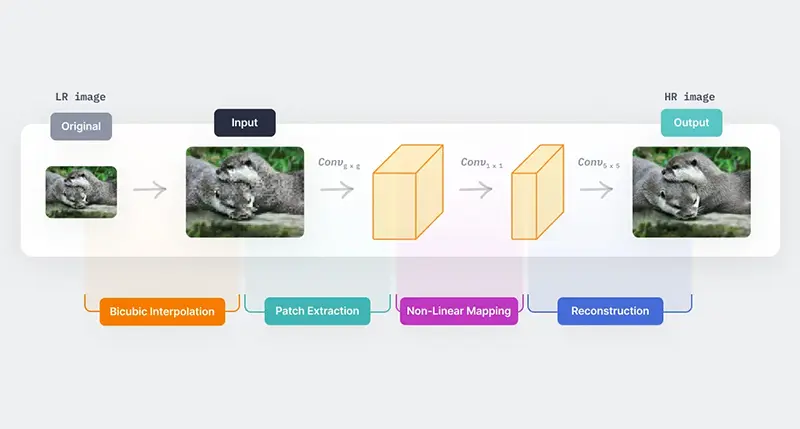
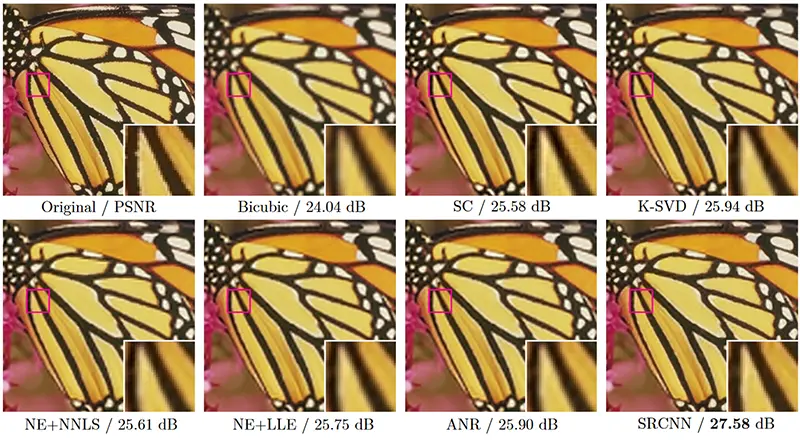
مثالی از نتایج به دست آمده توسط مدل SRCNN در مقایسه با همتایان آن در تصویر زیر نشان داده شده است.
وظیفه 2: بازسازی تصویر (Image Restoration)
کیفیت تصاویر میتواند به دلایل مختلفی کاهش یابد، بهویژه عکسهایی که از دوران قبل از ذخیرهسازی ابری گرفته شدهاند. برای مثال، تصاویری که از نسخههای فیزیکی قدیمی گرفته شدهاند، معمولاً دارای خط و خش هستند.

بازسازی تصویر بهویژه جذاب است زیرا تکنیکهای پیشرفته در این زمینه میتوانند اسناد تاریخی آسیبدیده را بازسازی کنند. الگوریتمهای بازسازی تصویر مبتنی بر یادگیری عمیق میتوانند بخشهای بزرگی از اطلاعات از دست رفته را در اسناد پاره یا خرابشده بازیابی کنند.

برای مثال، درونیابی تصویر (Image Inpainting) زیرمجموعهای از این دسته است و فرآیندی است که در آن پیکسلهای از دست رفته در تصویر پر میشوند. این کار میتواند با استفاده از الگوریتم سنتز بافت (Texture Synthesis) انجام شود که بافتهای جدیدی را برای پر کردن پیکسلهای از دست رفته تولید میکند. با این حال، مدلهای مبتنی بر یادگیری عمیق به دلیل قابلیتهای بالای تشخیص الگو، انتخاب اصلی هستند.
یک مثال از چارچوب درونیابی تصویر (بر اساس خودرمزگذار U-Net) در یک مقاله پیشنهاد شده است که از یک رویکرد دو مرحلهای برای حل این مشکل استفاده میکند: یک مرحله تخمین اولیه و یک مرحله بهبود. ویژگی اصلی این شبکه، لایه توجه معنایی همگن (CSA) است که نواحی مسدودشده در تصاویر ورودی را از طریق بهینهسازی تکراری پر میکند. معماری این مدل پیشنهادی در تصویر زیر نشان داده شده است.
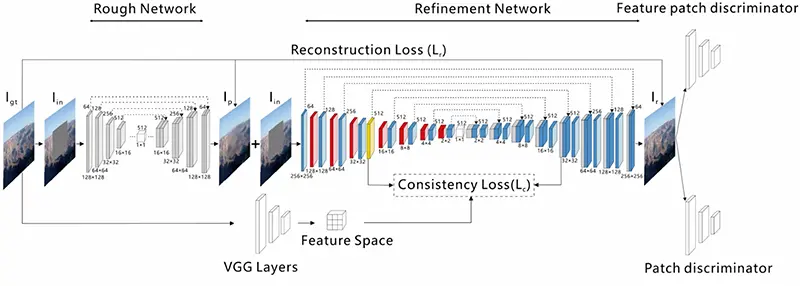
نتایج مثالهایی که توسط نویسندگان و سایر مدلهای رقابتی به دست آمدهاند نیز در تصویر زیر نمایش داده شدهاند.

وظیفه 3: بخش بندی تصویر (Image Segmentation)
بخش بندی تصویر (Image Segmentation) فرآیندی است که در آن تصویر به چندین بخش یا ناحیه تقسیم میشود. هر بخش نماینده یک شیء متفاوت در تصویر است و بخشبندی تصویر اغلب به عنوان یک مرحله پیش پردازشی برای تشخیص اشیاء استفاده میشود.
الگوریتمهای زیادی برای بخش بندی تصویر وجود دارند، اما یکی از رایجترین رویکردها استفاده از آستانهگذاری (Thresholding) است. بهعنوان مثال، آستانهگذاری باینری فرآیند تبدیل یک تصویر به یک تصویر باینری است که در آن هر پیکسل یا سیاه است یا سفید. مقدار آستانه به گونهای انتخاب میشود که تمامی پیکسلهایی که مقدار روشنایی آنها کمتر از مقدار آستانه است سیاه شوند و تمامی پیکسل هایی که روشنایی آنها بالاتر از آستانه است سفید شوند. این کار باعث میشود که اشیاء در تصویر به صورت بخشهای سیاه و سفید مجزا بخش بندی شوند.
مثالی از آستانهگذاری باینری با مقدار آستانه 127 در تصویر زیر نشان داده شده است.

در آستانهگذاری چندسطحی، همانطور که از نام آن پیداست، بخشهای مختلف تصویر به سطوح مختلفی از رنگ خاکستری تبدیل میشوند. این مقاله، بهعنوان مثال، از آستانهگذاری چندسطحی برای بخشبندی MRI مغز استفاده کرده است، که نمونهای از آن در تصویر زیر نشان داده شده است.
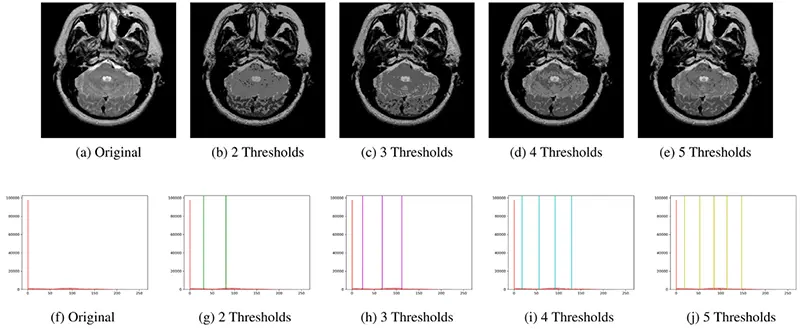
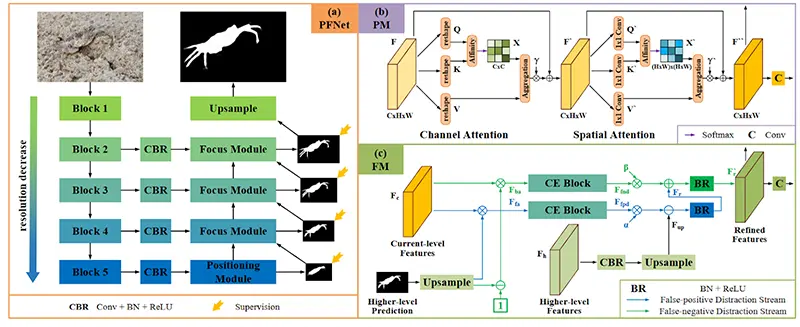
تکنیک های مدرن از الگوریتمهای خودکار بخش بندی تصویر با استفاده از یادگیری عمیق برای مشکلات بخشبندی باینری و چندسطحی استفاده میکنند. بهعنوان مثال، PFNet (Positioning and Focus Network) یک مدل مبتنی بر شبکه عصبی کانولوشنی است که مشکل بخشبندی اشیاء استتار شده را حل میکند. این مدل شامل دو ماژول کلیدی است:
- ماژول موقعیتیابی (PM) که برای تشخیص اشیاء طراحی شده است (که شبیه به شکارچیانی عمل میکند که بهطور تقریبی موقعیت شکار را شناسایی میکنند)؛
- ماژول تمرکز (FM) که وظیفه بهبود نتایج اولیه بخشبندی را با تمرکز روی نواحی مبهم بر عهده دارد. معماری مدل PFNet در تصویر زیر نشان داده شده است.
نتایج به دست آمده توسط مدل PFNet که عملکرد بهتری نسبت به مدل های پیشرفته همتراز خود داشته است، در تصویر زیر نمایش داده شده است.

وظیفه 4: تشخیص اشیاء (Object Detection)
تشخیص اشیاء (Object Detection) وظیفه شناسایی اشیاء در یک تصویر است و اغلب در کاربردهایی مانند امنیت و نظارت استفاده میشود. الگوریتمهای زیادی برای تشخیص اشیاء وجود دارند، اما رایجترین رویکرد استفاده از مدلهای یادگیری عمیق، بویژه شبکه های عصبی کانولوشنی (CNN) است.
شبکه های عصبی کانولوشنی نوعی از شبکههای عصبی مصنوعی هستند که بهطور خاص برای وظایف پردازش تصویر طراحی شدهاند، زیرا عملیات کانولوشن در آنها به کامپیوتر این امکان را میدهد که بخشهایی از تصویر را بهطور همزمان ببیند، بهجای پردازش پیکسل به پیکسل. CNN هایی که برای تشخیص اشیاء آموزش داده شدهاند، خروجی یک جعبه محدودکننده (Bounding Box) را تولید میکنند که مکان شیء تشخیص دادهشده در تصویر را نشان می دهد و برچسب دسته آن را نیز مشخص میکند.
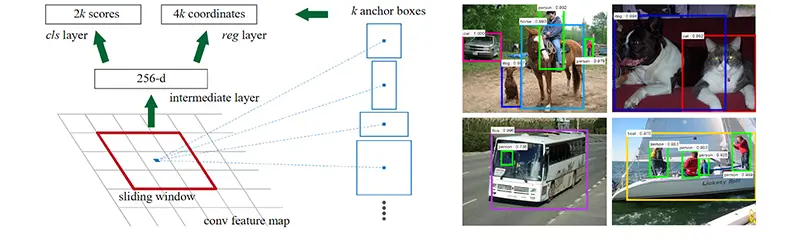
به عنوان مثال، مدل محبوب Faster R-CNN (Region-based Convolutional Neural Network) یک شبکه کاملاً کانولوشنی و قابل آموزش از ابتدا است. مدل Faster R-CNN بین تنظیم دقیق برای وظیفه پیشنهاد منطقه (پیش بینی نواحی در تصویر که ممکن است یک شیء در آن وجود داشته باشد) و سپس تنظیم دقیق برای تشخیص شیء (تشخیص اینکه چه شیای در آن وجود دارد) متناوب می شود و در حین حفظ پیشنهادها، این کار را انجام میدهد. معماری و برخی از مثال های پیشنهاد منطقه در تصویر زیر نشان داده شده است.
وظیفه 5: فشرده سازی تصویر (Image Compression)
فشرده سازی تصویر فرآیند کاهش اندازه فایل یک تصویر است در حالی که سعی میشود کیفیت تصویر حفظ شود. این کار برای صرفهجویی در فضای ذخیره سازی، بهویژه برای اجرای الگوریتم های پردازش تصویر بر روی دستگاههای موبایل و لبه (Edge Devices)، یا برای کاهش پهنای باند مورد نیاز برای انتقال تصویر انجام میشود.
رویکردهای سنتی از الگوریتمهای فشردهسازی با تلفات (Lossy Compression) استفاده میکنند که با کاهش کیفیت تصویر، حجم فایل آن را کاهش میدهند. بهعنوان مثال، فرمت JPEG از تبدیل کسینوسی گسسته (DCT) برای فشرده سازی تصویر استفاده میکند.
رویکردهای مدرن در فشرده سازی تصویر از یادگیری عمیق برای رمزگذاری تصاویر به فضای ویژگیهای با ابعاد کمتر و سپس بازسازی آن در سمت گیرنده با استفاده از شبکه رمزگشایی استفاده میکنند. این مدلها که به خودرمزگذارها (Autoencoders) معروف هستند، از یک شاخه رمزگذار که یک طرح رمزگذاری کارآمد را یاد میگیرد و یک شاخه رمزگشا که سعی میکند تصویر را بدون از دست دادن اطلاعات از ویژگیهای رمزگذاریشده بازیابی کند، تشکیل می شوند.
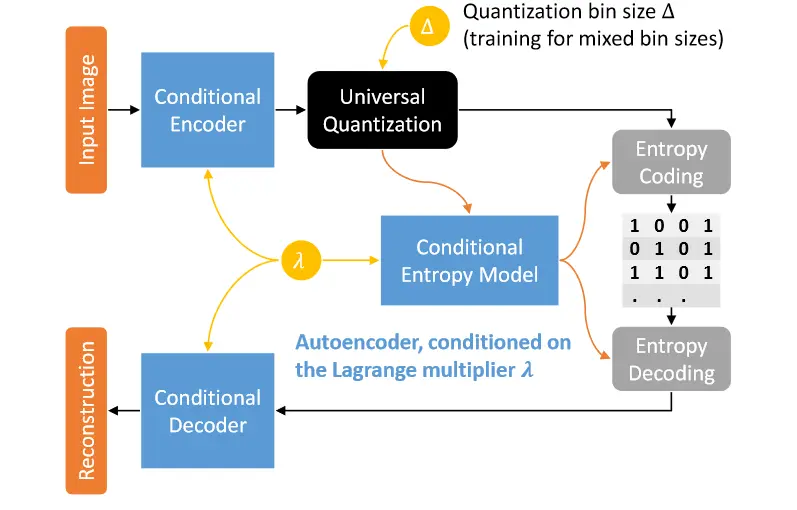
برای مثال، این مقاله یک چارچوب فشرده سازی تصویر با نرخ متغیر با استفاده از خودرمزگذار شرطی (Conditional Autoencoder) پیشنهاد کرده است. خودرمزگذار شرطی بر اساس ضریب لاگرانژ (Lagrange Multiplier) تنظیم شده است، یعنی شبکه ضریب لاگرانژ را بهعنوان ورودی میگیرد و نمایشی نهفته تولید میکند که نرخ آن به مقدار ورودی وابسته است. نویسندگان همچنین شبکه را با اندازههای مختلط درونیابی برای تنظیم نرخ فشردهسازی آموزش دادهاند. چارچوب آنها در تصویر زیر نشان داده شده است.
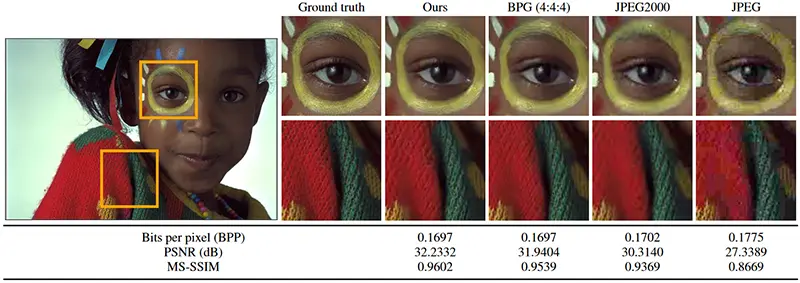
نویسندگان نتایج برتری نسبت به روشهای محبوب مانند JPEG به دست آوردهاند، هم از لحاظ کاهش بیت در هر پیکسل و هم در کیفیت بازسازی. مثالی از این نتایج در تصویر زیر نشان داده شده است.
وظیفه 6: دستکاری تصویر (Image Manipulation)
دستکاری تصویر فرآیند تغییر یک تصویر برای تغییر ظاهر آن است. این کار ممکن است به دلایل مختلفی انجام شود، مانند حذف یک شیء ناخواسته از تصویر یا افزودن شیئی که در تصویر موجود نیست. طراحان گرافیک معمولاً از این روشها برای ایجاد پوسترها، فیلمها و غیره استفاده میکنند.
یک مثال از دستکاری تصویر، انتقال سبک عصبی (Neural Style Transfer) است که تکنیکی است که از مدلهای یادگیری عمیق برای انطباق یک تصویر با سبک تصویر دیگری استفاده میکند. بهعنوان مثال، یک تصویر عادی میتواند به سبک «شب پرستاره» ونگوگ منتقل شود. انتقال سبک عصبی همچنین به هوش مصنوعی این امکان را میدهد که هنر تولید کند.

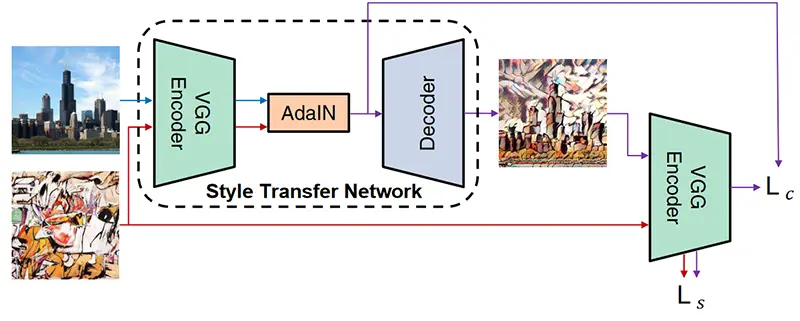
یک مثال از چنین مدلی که در این مقاله پیشنهاد شده، مدلی است که قادر به انتقال سبکهای جدید بهصورت زمان واقعی است (در حالی که رویکردهای دیگر معمولاً زمان استنتاج طولانیتری دارند) با استفاده از یک چارچوب مبتنی بر خودرمزگذار. نویسندگان یک لایه نرمال سازی تطبیقی (AdaIN) را پیشنهاد کردهاند که میانگین و واریانس ورودی محتوایی (تصویری که باید تغییر کند) را برای انطباق با آنچه در ورودی سبک (تصویری که سبک آن باید اتخاذ شود) تنظیم میکند. خروجی AdaIN سپس به فضای تصویر رمزگشایی میشود تا تصویر نهایی با انتقال سبک به دست آید. نمای کلی این چارچوب در تصویر زیر نشان داده شده است.
نمونههایی از تصاویری که به سبکهای هنری دیگر منتقل شدهاند، در زیر نشان داده شده و با روشهای مدرن موجود مقایسه شدهاند.

وظیفه 7: تولید تصویر (Image Generation)
سنتز تصاویر جدید یکی دیگر از وظایف مهم در پردازش تصویر است، بهویژه در الگوریتم های یادگیری عمیق که به مقادیر زیادی از دادههای برچسب گذاری شده برای آموزش نیاز دارند. روشهای تولید تصویر معمولاً از شبکههای مولد تخاصمی (GANs) که یک معماری خاص شبکه عصبی است، استفاده میکنند.
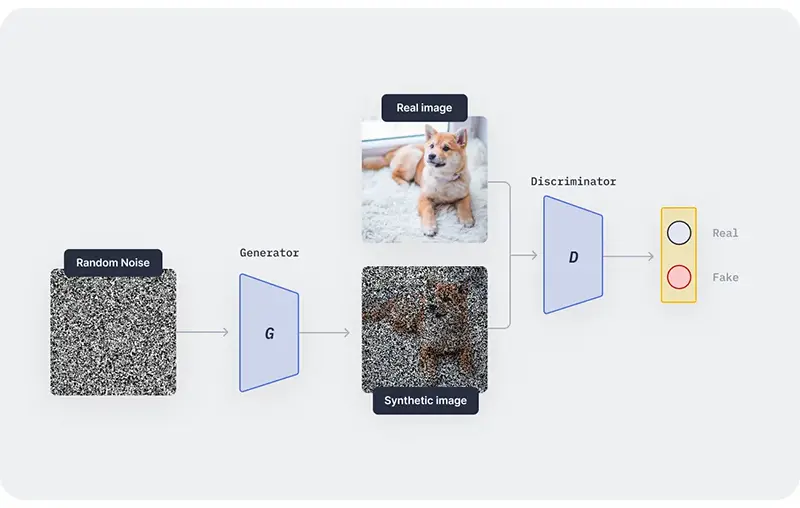
GANها شامل دو مدل جداگانه هستند: تولید کننده (Generator) که تصاویر مصنوعی را تولید میکند و تشخیص دهنده (Discriminator) که سعی میکند تصاویر مصنوعی را از تصاویر واقعی تشخیص دهد. تولید کننده سعی میکند تصاویری را سنتز کند که بهقدری واقعی به نظر برسند که تشخیص دهنده را فریب دهد و تشخیص دهنده برای بهتر نقد کردن اینکه آیا یک تصویر مصنوعی یا واقعی است، آموزش میبیند. این بازی تخاصمی به تولید کننده اجازه میدهد تا پس از چندین تکرار، تصاویر عکاسی واقعی تولید کند که سپس می توانند برای آموزش سایر مدلهای یادگیری عمیق استفاده شوند.
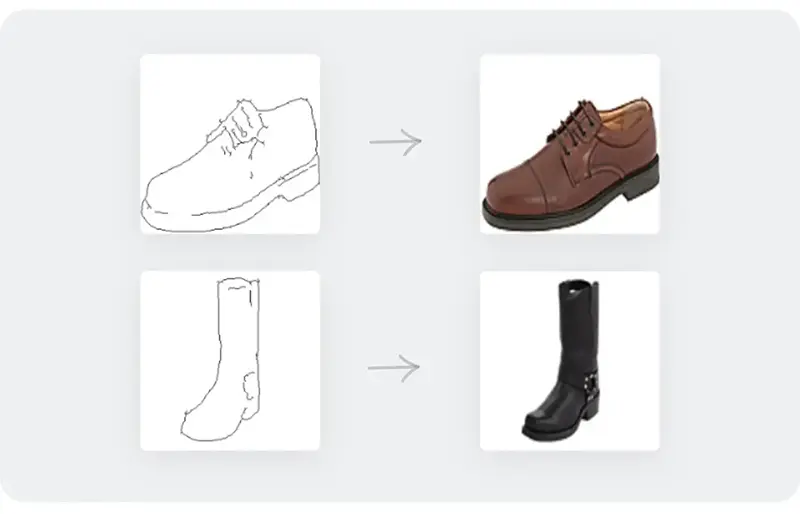
وظیفه 8: ترجمه تصویر به تصویر (Image-to-Image Translation)
ترجمه تصویر به تصویر یک کلاس از مسائل بینایی و گرافیک است که هدف آن یادگیری نقشه برداری بین یک تصویر ورودی و یک تصویر خروجی با استفاده از مجموعه آموزشی از جفتهای تصویری هم راستا است. بهعنوان مثال، یک طراحی دستی میتواند بهعنوان ورودی کشیده شود تا یک تصویر واقعی از شیء نمایش داده شده در طراحی بهعنوان خروجی بهدست آید، همانطور که در تصویر زیر نشان داده شده است.
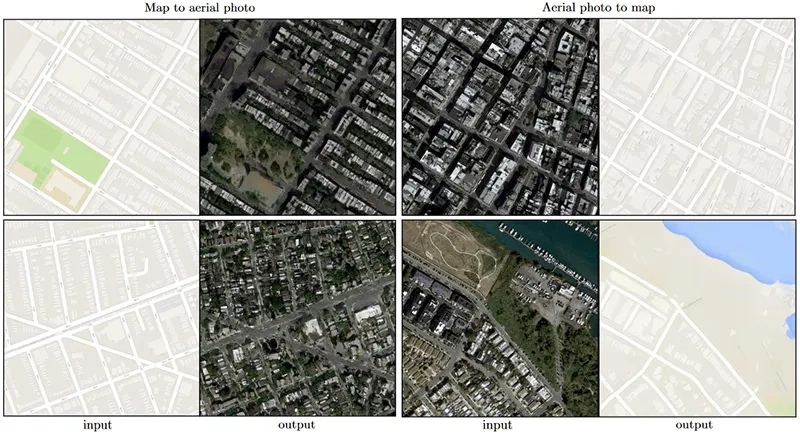
Pix2pix مدل معروفی در این حوزه است که از مدل GAN شرطی (cGAN) برای ترجمه تصویر به تصویر بطور عمومی استفاده میکند؛ یعنی مسائل مختلف در پردازش تصویر مانند جداسازی معنایی، ترجمه طراحی به تصویر و رنگآمیزی تصاویر، همگی توسط همان شبکه حل میشوند. cGANها شامل تولید شرطی تصاویر توسط یک مدل تولید کننده هستند. بهعنوان مثال، تولید تصویر میتواند بر اساس یک برچسب کلاس شرطی شود تا تصاویری خاص برای آن کلاس تولید شود.

Pix2pix شامل یک شبکه تولیدکننده U-Net و یک شبکه تشخیص دهنده PatchGAN است که بهجای مدل های سنتی GAN، تکههای NxN از تصویر را بهعنوان ورودی میگیرد تا پیشبینی کند که آیا واقعی است یا جعلی. نویسندگان ادعا میکنند که چنین تشخیص دهندهای محدودیتهای بیشتری را اعمال میکند که جزئیات با فرکانس بالا و تیز را تشویق میکند. نمونه هایی از نتایج بدست آمده توسط مدل pix2pix در وظایف تصویر به نقشه و نقشه به تصویر در زیر نشان داده شده است.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]
سلام وقت به خیر
ممنون از مطلب مفیدتون
یه سوالی داشتم
Smoothening image در فارسی چه کلمه معادلی داره؟
نرم یا صاف کردن تصویر میشه؟
یا کلمه ای مثل smoothing effect رو به چه صورت باید ترجمه کرد؟
ممنون میشم پاسخ بدین
سلام وقتتون بخیر خیلی ممنون از انرژی مثبت شما
Smoothening image=اثر نویز زدایی
smoothing effect= تاثیر هموار سازی
تقریبا به این شکل ترجمه بشه به مفهوم اصلی آن نزدیک تره بازهم سوالی بود در خدمت هستیم
سپاس از مطالب بسیار مفید و کاربردی که به اشتراک گذاشتید
سلام و عرض ادب
ممنون از دلگرمی شما بسیار خرسندیم که مفید واقع شده براتون