
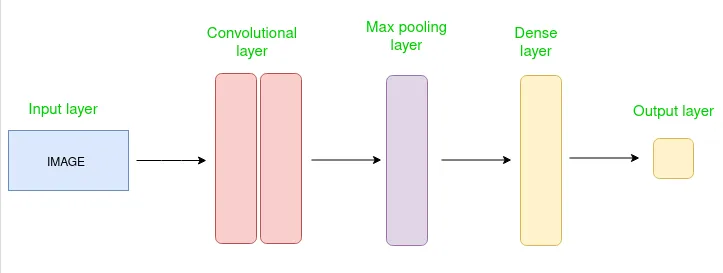
شبکه عصبی کانولوشنی (CNN) چیست؟
 چیست؟")
چکیده مقاله:
شبکه عصبی کانولوشنی (CNN) یک معماری شبکه عصبی عمیق است که به طور گسترده در حوزه بینایی کامپیوتر استفاده می شود. بینایی کامپیوتر شاخه ای از هوش مصنوعی است که به کامپیوترها این امکان را می دهد تا داده های تصویری یا بصری را درک و تفسیر کنند. هنگامی که صحبت از یادگیری ماشین می شود، شبکه های عصبی مصنوعی عملکرد بسیار خوبی دارند. این شبکه ها در انواع داده ها مانند تصاویر، صوت و متن مورد استفاده قرار می گیرند. انواع مختلفی از شبکه های عصبی برای اهداف مختلف طراحی شده اند. به عنوان مثال، برای پیش بینی توالی کلمات از شبکه های عصبی بازگشتی (RNN)، به ویژه LSTM استفاده می شود. به طور مشابه، برای طبقه بندی تصاویر، از شبکه های عصبی کانولوشنی استفاده می گردد. در ادامه به بررسی کامل CNN ها می پردازیم با ما همراه باشید.
شبکه عصبی کانولوشنی چیست؟
شبکه عصبی کانولوشنی برای وظایف طبقه بندی تصاویر و شناسایی اشیا از داده های سه بعدی استفاده می شود.
شبکه های عصبی زیرمجموعه ای از یادگیری ماشین هستند و در قلب الگوریتم های یادگیری عمیق قرار دارند. آن ها از لایه های گره ای تشکیل شده اند که شامل یک لایه ورودی، یک یا چند لایه مخفی و یک لایه خروجی می باشند. هر گره به دیگری متصل است و دارای وزنی و آستانه ای مشخص می باشد. اگر خروجی هر گره خاصی از مقدار آستانه تعیین شده بیشتر باشد، آن گره فعال شده و داده ها را به لایه بعدی شبکه ارسال می کند. در غیر این صورت، هیچ داده ای به لایه بعدی منتقل نمی شود.
در حالی که ما عمدتا بر روی شبکه های پیش خور تمرکز داشتیم، انواع مختلفی از شبکه های عصبی وجود دارند که برای موارد استفاده و انواع داده های مختلف به کار می روند. به عنوان مثال، شبکه های عصبی بازگشتی برای پردازش زبان طبیعی و تشخیص گفتار معمول هستند، در حالی که شبکه های عصبی کانوالوشنی (ConvNets یا CNNs) بیشتر برای طبقه بندی و وظایف بینایی کامپیوتر استفاده می شوند.
پیش از ظهور CNN ها، روش های دستی و زمان بر استخراج ویژگی برای شناسایی اشیا در تصاویر به کار می رفتند. با این حال، شبکه های عصبی کانولوشنی اکنون رویکردی مقیاس پذیرتر برای طبقه بندی تصاویر و شناسایی اشیا ارائه می دهند که از اصول جبر خطی، به ویژه ضرب ماتریسی، برای شناسایی الگوها در یک تصویر بهره می برند. البته این شبکه ها ممکن است به لحاظ محاسباتی پرهزینه باشند و نیاز به واحدهای پردازش گرافیکی (GPU) برای آموزش مدل ها داشته باشند.
شبکه های عصبی: لایه ها و عملکرد
در یک شبکه عصبی معمولی، سه نوع لایه وجود دارد:
- لایه ورودی:
این لایه همان جایی است که ورودی به مدل داده می شود. تعداد نورون ها در این لایه برابر با تعداد کل ویژگی های داده ما می باشد (در مورد تصاویر، تعداد پیکسل ها). - لایه های پنهان:
خروجی لایه ورودی به لایه پنهان ارسال می شود. بسته به مدل و اندازه داده ها، می توان تعداد زیادی لایه پنهان داشت. هر لایه پنهان می تواند تعداد نورون های متفاوتی داشته باشد که معمولا بیشتر از تعداد ویژگی ها است. خروجی هر لایه با ضرب ماتریسی خروجی لایه قبلی در وزن های قابل یادگیری آن لایه و سپس اضافه کردن بایاس های قابل یادگیری و اعمال تابع فعال سازی محاسبه می شود که باعث غیرخطی شدن شبکه می گردد. - لایه خروجی:
خروجی لایه پنهان به یک تابع لجستیک مانند سیگموید یا Softmax داده می شود که خروجی هر کلاس را به امتیاز احتمالی تبدیل می کند.
داده به مدل داده می شود و خروجی از هر لایه با استفاده از این گام ها محاسبه می شود که به آن پیش رو (feedforward) گفته می شود. سپس خطا با استفاده از یک تابع خطا محاسبه می شود. برخی از توابع خطای رایج عبارتند از آنتروپی متقاطع و خطای مربعی. این تابع خطا عملکرد شبکه را اندازه گیری می کند. پس از آن، مدل با محاسبه مشتقات بازپس انتشار می یابد. این گام که به بازپس انتشار (Backpropagation) معروف است، برای به حداقل رساندن خطا استفاده می شود.
شبکه های عصبی کانولوشنی چگونه کار می کنند؟
شبکه عصبی کانولوشنی (CNN) نسخه توسعه یافته شبکه های عصبی مصنوعی (ANN) است که عمدتا برای استخراج ویژگی از مجموعه داده هایی با ساختار شبکه ای استفاده می شود. برای مثال، مجموعه داده های بصری مانند تصاویر یا ویدیوها که الگوهای داده در آن ها نقش مهمی دارند.
شبکه عصبی کانوالوشنی به دلیل عملکرد برتر خود با ورودی های تصویری، گفتاری یا سیگنال های صوتی از سایر شبکه های عصبی متمایز می شود. سه نوع اصلی لایه دارد که عبارتند از:
- لایه کانولوشن
- لایه تجمع (Pooling)
- لایه کاملا متصل (FC)
لایه کانوالوشن اولین لایه یک شبکه کانوالوشنی است. در حالی که این لایه ها می توانند با لایه های کانوالوشنی اضافی یا لایه های تجمع دنبال شوند، لایه کاملا متصل آخرین لایه می باشد. با هر لایه، پیچیدگی CNN افزایش می یابد و بخش های بیشتری از تصویر شناسایی می شود. لایه های اولیه بر ویژگی های ساده مانند رنگ ها و لبه ها تمرکز می کنند. با پیشرفت داده های تصویری در لایه های شبکه عصبی کانوالوشنی، شروع به شناسایی عناصر یا اشکال بزرگتر از شیء می کند تا در نهایت شیء مورد نظر را شناسایی نماید.
شبکه های عصبی کانولوشنی یا covnet ها شبکه هایی هستند که پارامترهای خود را به اشتراک می گذارند. فرض کنید شما یک تصویر دارید. این تصویر می تواند به صورت یک مکعب با طول، عرض (ابعاد تصویر) و ارتفاع (کانال های قرمز، سبز و آبی تصویر) نمایش داده شود.
حالا فرض کنید یک ناحیه کوچک از این تصویر را برداشته و یک شبکه عصبی کوچک، به نام فیلتر یا هسته، روی آن اجرا کنید. این فیلتر خروجی هایی تولید می کند که به صورت عمودی نمایش داده می شوند. حال اگر این فیلتر را روی کل تصویر جابجا کنید، به نتیجه ای خواهید رسید که یک تصویر جدید با عرض، ارتفاع و عمق متفاوت ایجاد می کند. به جای فقط کانال های R، G و B، اکنون کانال های بیشتری با عرض و ارتفاع کمتر دارید. این عملیات به عنوان کانوالوشن شناخته می شود.
اگر اندازه ناحیه انتخاب شده برابر با اندازه کل تصویر باشد، شبکه تبدیل به یک شبکه عصبی معمولی می شود. به دلیل این ناحیه کوچک، وزن های کمتری در شبکه وجود دارد.
لایه کانولوشن
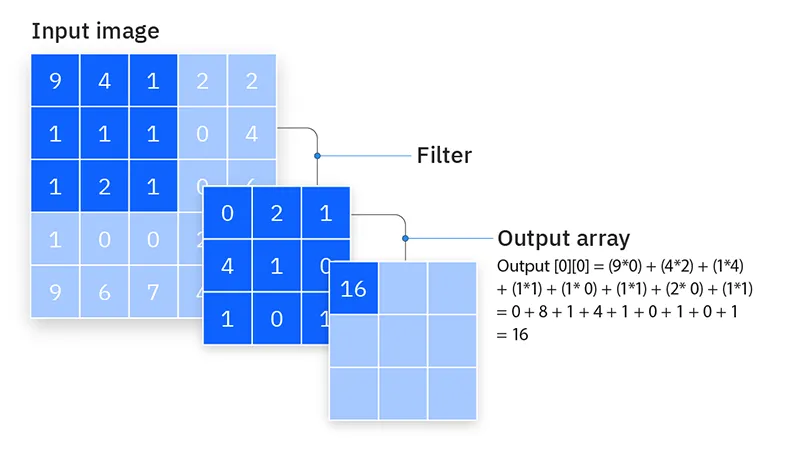
لایه کانوالوشن بخش اصلی یک شبکه عصبی کانولوشنی است و جایی است که بخش عمده محاسبات انجام می شود. این لایه به چندین مؤلفه نیاز دارد که شامل داده های ورودی، یک فیلتر و یک نقشه ویژگی می باشند. فرض کنید ورودی یک تصویر رنگی باشد که از یک ماتریس سه بعدی پیکسل ها تشکیل شده است. این بدان معنا است که ورودی دارای سه بعد خواهد بود: ارتفاع، عرض و عمق که با RGB در تصویر مطابقت دارند.
ما همچنین یک آشکارساز ویژگی داریم که با نام های هسته یا فیلتر نیز شناخته می شود و در نواحی مختلف تصویر حرکت می کند تا بررسی کند که آیا ویژگی مورد نظر موجود است یا خیر. این فرآیند به عنوان کانوالوشن شناخته می شود. آشکارساز ویژگی یک آرایه دو بعدی (2D) از وزن ها است که بخشی از تصویر را نشان می دهد. اندازه فیلتر معمولا ماتریسی 3×3 است که اندازه ناحیه پذیرش را نیز تعیین می کند. فیلتر سپس بر روی بخشی از تصویر اعمال می شود و یک حاصلضرب نقطه ای بین پیکسل های ورودی و فیلتر محاسبه می شود.
این حاصلضرب نقطه ای به آرایه خروجی وارد می شود. سپس فیلتر با یک گام حرکت کرده و فرآیند تکرار می شود تا هسته کل تصویر را بپوشاند. خروجی نهایی از مجموعه حاصلضرب های نقطه ای بین ورودی و فیلتر به عنوان نقشه ویژگی، نقشه فعال سازی یا ویژگی کانولوشن شناخته می شود.
وزن ها در آشکارساز ویژگی هنگام حرکت در تصویر ثابت می مانند که به این فرآیند به اشتراک گذاری پارامتر نیز گفته می شود. برخی از پارامترها مانند مقادیر وزن، در طول فرآیند آموزش از طریق پس انتشار و نزول گرادیان تنظیم می شوند. با این حال، سه ابرپارامتر وجود دارند که حجم خروجی را قبل از شروع آموزش شبکه عصبی تعیین می کنند:
- تعداد فیلترها: تعداد فیلترها عمق خروجی را تعیین می کنند. برای مثال، سه فیلتر مختلف سه نقشه ویژگی متفاوت تولید می کنند که عمقی برابر با سه ایجاد می کند.
- گام (Stride): فاصله یا تعداد پیکسل هایی است که هسته بر روی ماتریس ورودی حرکت می کند. در حالی که مقادیر گام برابر با دو یا بیشتر نادر هستند، گام بزرگتر خروجی کوچکتری تولید می کند.
- پد صفر (Zero-padding): معمولا هنگامی استفاده می شود که فیلترها با تصویر ورودی تناسب ندارند. این کار تمامی عناصری که خارج از ماتریس ورودی قرار می گیرند را به صفر تنظیم می کند و خروجی بزرگتر یا هم اندازه با ورودی ایجاد می کند. انواع پدینگ عبارتند از:
- پدینگ معتبر (Valid padding): این مورد بدون پدینگ است و در این حالت، کانوالوشن آخر در صورتی که ابعاد هماهنگ نباشند، حذف می شود.
- پدینگ یکسان (Same padding): این نوع پدینگ تضمین می کند که لایه خروجی با اندازه لایه ورودی برابر باشد.
- پدینگ کامل (Full padding): این نوع پدینگ اندازه خروجی را با افزودن صفرها به حاشیه های ورودی افزایش می دهد.
پس از هر عملیات کانوالوشن، یک شبکه عصبی کانولوشنی از یک تبدیل ReLU (واحد خطی اصلاح شده) بر روی نقشه ویژگی استفاده می کند که به مدل غیرخطی بودن اضافه می کند.
لایه کانوالوشن اضافی
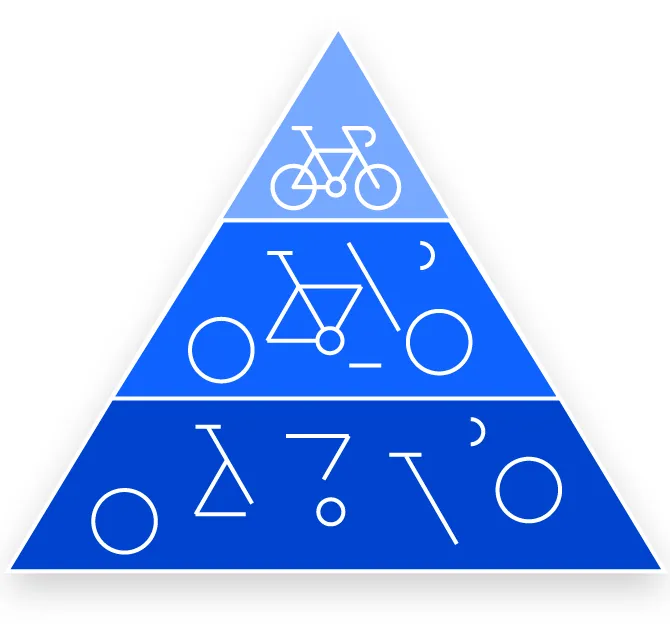
همان طور که پیش تر ذکر شد، یک لایه کانوالوشن دیگر می تواند پس از لایه کانولوشن اولیه قرار گیرد. زمانی که این اتفاق رخ می دهد، ساختار شبکه عصبی کانولوشنی (CNN) می تواند به صورت سلسله مراتبی شکل گیرد، زیرا لایه های بعدی می توانند پیکسل های درون نواحی پذیرش لایه های قبلی را مشاهده کنند.
برای مثال، فرض کنید که قصد داریم تشخیص دهیم آیا یک تصویر حاوی دوچرخه است یا خیر. می توان دوچرخه را به عنوان مجموع اجزای آن در نظر گرفت. این اجزا شامل بدنه، فرمان، چرخ ها، پدال ها و غیره می باشند. هر جزء دوچرخه یک الگوی سطح پایین در شبکه عصبی محسوب می شود و ترکیب این اجزا یک الگوی سطح بالاتر را تشکیل می دهد که در نتیجه یک سلسله مراتب ویژگی در CNN ایجاد می کند. در نهایت، لایه کانولوشن تصویر را به مقادیر عددی تبدیل می کند و به شبکه عصبی اجازه می دهد الگوهای مرتبط را تفسیر و استخراج نماید.
لایه تجمع (Pooling)
لایه های تجمع، که به عنوان کاهش نمونه نیز شناخته می شوند، به کاهش ابعاد داده ها و کاهش تعداد پارامترهای ورودی می پردازند. مشابه لایه کانوالوشن، عملیات تجمع نیز یک فیلتر را بر روی کل ورودی حرکت می دهد، اما تفاوت در این است که این فیلتر دارای وزنی نمی باشد. در عوض، هسته از یک تابع جمع بندی برای مقادیر درون ناحیه پذیرش استفاده کرده و آرایه خروجی را پر می کند.
دو نوع اصلی تجمع عبارتند از:
- تجمع حداکثری (Max pooling): هنگامی که فیلتر بر روی ورودی حرکت می کند، بیشترین مقدار پیکسل را انتخاب کرده و به آرایه خروجی ارسال می کند. این روش نسبت به تجمع میانگین معمولا بیشتر استفاده می شود.
- تجمع میانگین (Average pooling): در این روش، فیلتر هنگام حرکت بر روی ورودی، میانگین مقادیر درون ناحیه پذیرش را محاسبه کرده و به آرایه خروجی ارسال می کند.
اگرچه اطلاعات زیادی در لایه تجمع از دست می رود، این لایه مزایای بسیاری برای شبکه عصبی کانولوشنی دارد. این مزایا شامل کاهش پیچیدگی، بهبود کارایی و کاهش خطر بیش برازش می باشند.
لایه کاملا متصل (Fully-connected)
نام لایه کاملا متصل به خوبی عملکرد آن را توصیف می کند. همان طور که پیش تر اشاره شد، مقادیر پیکسل ورودی در لایه های جزئی متصل مستقیما به لایه خروجی متصل نمی شوند. اما در لایه کاملا متصل، هر گره در لایه خروجی به طور مستقیم به یک گره در لایه قبلی متصل می باشد.
این لایه وظیفه طبقه بندی را بر اساس ویژگی های استخراج شده از طریق لایه های قبلی و فیلترهای آن ها انجام می دهد. در حالی که لایه های کانولوشن و تجمع عمدتا از توابع ReLU استفاده می کنند، لایه های کاملا متصل معمولا از تابع فعال سازی Softmax برای طبقه بندی ورودی ها به صورت مناسب استفاده می کنند و احتمالاتی بین 0 تا 1 تولید می نمایند.
انواع شبکه های عصبی کانولوشنی
کنیهیکو فوکوشیما و یان لکون پایه های تحقیقاتی پیرامون شبکه های عصبی کانوالوشنی را در کارهای خود در سال 1980 و مقاله “پس انتشار به کار رفته برای تشخیص کد پستی دست نویس” در سال 1989 بنیان گذاری کردند. به ویژه، یان لکون با موفقیت از پس انتشار برای آموزش شبکه های عصبی به منظور شناسایی و تشخیص الگوها در مجموعه ای از کدهای پستی دست نویس استفاده کرد. او تحقیقات خود را در دهه 1990 با تیم خود ادامه داد و در نهایت به معماری “LeNet-5” رسید که همان اصول تحقیقات قبلی را برای تشخیص اسناد به کار برد.
از آن زمان، معماری های مختلفی از شبکه عصبی کانولوشن با معرفی مجموعه داده های جدید مانند MNIST و CIFAR-10 و رقابت هایی مانند چالش شناسایی بصری مقیاس بزرگ ImageNet (ILSVRC) پدیدار شدند. برخی از این معماری ها شامل موارد زیر می باشند:
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
- ZFNet
با این حال، LeNet-5 به عنوان معماری کلاسیک CNN شناخته می شود.
CNN و بینایی کامپیوتر
شبکه های عصبی کانوالوشنی، نیروی محرکه تشخیص تصویر و وظایف بینایی کامپیوتر می باشند. بینایی کامپیوتر یکی از شاخه های هوش مصنوعی (AI) است که به کامپیوترها و سیستم ها این امکان را می دهد تا اطلاعات معناداری از تصاویر دیجیتال، ویدیوها و سایر ورودی های بصری استخراج کنند و بر اساس این ورودی ها اقدامات مناسب را انجام دهند. این قابلیت توصیه کردن، بینایی کامپیوتر را از وظایف تشخیص تصویر متمایز می کند.
امروزه برخی از کاربردهای رایج بینایی کامپیوتر عبارتند از:
- بازاریابی:
پلتفرم های شبکه های اجتماعی پیشنهاداتی در مورد افرادی که ممکن است در یک عکس پست شده باشند ارائه می دهند. این کار فرآیند برچسب گذاری دوستان در آلبوم های عکس را ساده تر می کند. - بهداشت و درمان:
بینایی کامپیوتر به فناوری های رادیولوژی اضافه شده است و به پزشکان کمک می کند تا تومورهای سرطانی را در آناتومی سالم بهتر شناسایی کنند. - خرده فروشی:
جستجوی بصری در برخی از پلتفرم های تجارت الکترونیکی گنجانده شده است که به برندها امکان می دهد اقلامی را پیشنهاد دهند که می توانند مکمل یک مجموعه لباس موجود باشند. - صنعت خودرو:
اگرچه عصر خودروهای بدون راننده هنوز به طور کامل فرا نرسیده است، اما فناوری های پایه ای آن به خودروها راه یافته است و از طریق قابلیت هایی مانند تشخیص خطوط جاده، ایمنی راننده و سرنشینان را بهبود بخشیده است.
مثال: اعمال شبکه عصبی کانوالوشنی بر روی یک تصویر
برای درک بهتر نحوه کار شبکه عصبی کانولوشنی، یک تصویر را در نظر می گیریم و عملیات لایه کانوالوشن، لایه فعال سازی و لایه تجمع را برای استخراج ویژگی های درونی آن اعمال می کنیم.
عکس ورودی

مراحل به شرح زیر می باشند:
- وارد کردن کتابخانه های مورد نیاز
- تنظیم پارامترها
- تعریف هسته (Kernel)
- بارگذاری تصویر و نمایش آن
- تغییر فرمت تصویر
- اعمال عملیات لایه کانولوشن و نمایش تصویر خروجی
- اعمال عملیات لایه فعال سازی و نمایش تصویر خروجی
- اعمال عملیات لایه تجمع و نمایش تصویر خروجی
کد پایتون
عکس خروجی

مزایا و معایب شبکه های عصبی کانوالوشنی
مزایا:
- تشخیص الگوها و ویژگی ها:
CNN ها در تشخیص الگوها و ویژگی ها در تصاویر، ویدیوها و سیگنال های صوتی عملکرد بسیار خوبی دارند. - پایداری نسبت به تغییرات:
این شبکه ها به تغییرات مکانی، چرخش و مقیاس حساسیت کمتری دارند. - آموزش سرتاسری:
نیازی به استخراج دستی ویژگی ها نیست؛ کل فرآیند از ورودی تا خروجی به صورت خودکار انجام می شود. - مدیریت داده های بزرگ:
توانایی کار با داده های بزرگ و دستیابی به دقت بالا را دارند.
معایب:
- هزینه محاسباتی بالا:
فرآیند آموزش این شبکه ها بسیار زمان بر است و به حافظه زیادی نیاز دارد. - خطر بیش برازش:
اگر داده کافی یا تنظیمات منظم سازی مناسب وجود نداشته باشد، این شبکه ها مستعد بیش برازش هستند. - نیاز به داده های برچسب گذاری شده زیاد:
برای عملکرد مطلوب به مقادیر زیادی داده با برچسب نیاز دارند. - تفسیرپذیری محدود:
درک آنچه که شبکه یاد گرفته است، دشوار است و اغلب به عنوان یک “جعبه سیاه” عمل می کند.
سوالات متداول
شبکه عصبی کانوالوشنی (CNN) چیست؟
شبکه عصبی کانولوشنی (CNN) نوعی از شبکه عصبی عمیق می باشد که برای تحلیل تصاویر و ویدیوها بسیار مناسب است. این شبکه ها با استفاده از لایه های کانوالوشن و تجمع، ویژگی هایی از تصاویر و ویدیوها استخراج کرده و از این ویژگی ها برای دسته بندی یا تشخیص اشیا و صحنه ها استفاده می کنند.
شبکه های عصبی کانولوشنی چگونه کار می کنند؟
CNN ها با اعمال مجموعه ای از لایه های کانولوشن و تجمع بر روی یک تصویر یا ویدیو ورودی کار می کنند. لایه های کانوالوشن ویژگی هایی از ورودی را از طریق اعمال یک فیلتر کوچک یا هسته (Kernel) استخراج می کنند. سپس لایه های تجمع داده های خروجی لایه های کانوالوشن را برای کاهش ابعاد و افزایش کارایی محاسباتی، کاهش اندازه می دهند.
تفاوت بین CNN و کانولوشن چیست؟
- CNN: یک نوع از شبکه های عصبی عمیق است که برای پردازش داده های شبکه مانند تصاویر طراحی شده و از لایه های کانوالوشن برای استخراج ویژگی ها استفاده می کند.
- کانوالوشن: عملیات ریاضی خاصی است که در CNN برای اعمال فیلترها بر داده های ورودی (مانند تصاویر) برای شناسایی الگوهایی مانند لبه ها یا بافت ها انجام می شود.
اصل اساسی CNN چیست؟
اصل اساسی شبکه عصبی کانولوشنی، یادگیری خودکار و استخراج ویژگی های سلسله مراتبی از داده های ورودی (معمولا تصاویر) از طریق استفاده از لایه های کانوالوشن می باشد.
کانولوشن چیست و انواع آن کدامند؟
کانوالوشن یک عملیات ریاضی است که در شبکه های عصبی کانولوشنی برای استخراج ویژگی ها از داده های ورودی (مانند تصاویر) اعمال می شود. در زمینه CNN، کانوالوشن شامل حرکت دادن یک فیلتر (Kernel) بر روی داده های ورودی، محاسبه حاصل ضرب داخلی بین فیلتر و یک بخش کوچک از داده های ورودی، و تولید یک نقشه ویژگی می باشد.
چند لایه در CNN وجود دارد؟
تعداد لایه ها در یک CNN ثابت نیست و بسته به معماری و وظیفه متفاوت می باشد.
هدف از استفاده از چندین لایه کانولوشن در یک CNN چیست؟
استفاده از چندین لایه کانوالوشن در یک CNN به شبکه اجازه می دهد تا ویژگی های پیچیده تری از تصویر یا ویدیو ورودی یاد بگیرد. لایه های اولیه ویژگی های ساده ای مانند لبه ها و گوشه ها را یاد می گیرند، در حالی که لایه های عمیق تر ویژگی های پیچیده تر مانند اشکال و اشیا را یاد می گیرند.
تفاوت بین لایه کانولوشن و لایه تجمع چیست؟
- لایه کانولوشن: ویژگی هایی را از یک تصویر یا ویدیو ورودی استخراج می کند.
- لایه تجمع: داده های خروجی لایه های کانوالوشن را کوچک تر می کند.
لایه های کانولوشن از فیلترهای مختلف برای استخراج ویژگی ها استفاده می کنند، در حالی که لایه های تجمع از روش هایی مانند ماکس تجمع (Max Pooling) و میانگین تجمع (Average Pooling) برای کاهش ابعاد داده بهره می برند.





مدیر2025-11-23T23:33:51+03:30نوامبر 23, 2025|0 Comments
هوش مصنوعی Grok یکی از جدیدترین و پیشرفته ترین ابزارهای هوش مصنوعی است که تجربه گفتگویی طبیعی و هوشمند را برای کاربران فراهم می کند. این سیستم نه تنها پاسخگوی سوالات روزمره است، بلکه [...]

مدیر2025-11-18T00:15:22+03:30نوامبر 18, 2025|0 Comments
هوش مصنوعی Gemini چیست؟ این سوال این روزها به یکی از پرجستجوترین موضوعات در فضای تکنولوژی تبدیل شده است، چون Gemini به عنوان پیشرفته ترین مدل هوش مصنوعی گوگل توانسته مرزهای پردازش زبان، تصویر، [...]

مدیر2025-11-07T00:34:24+03:30نوامبر 7, 2025|0 Comments
چکیده مقاله: E-E-A-T مخفف چهار واژهی Experience (تجربه)، Expertise (تخصص)، Authoritativeness (اعتبار) و Trustworthiness (قابلاعتماد بودن) است. این مفهوم توسط گوگل معرفی شده تا معیارهایی برای ارزیابی کیفیت محتوای وب سایت ها ارائه دهد. [...]

مدیر2025-11-06T00:58:39+03:30نوامبر 6, 2025|0 Comments
چکیده مقاله: GEO کلاه سیاه معبری است به دنیایی که وسوسه موفقیت سریع را با تکنیک های پرخطر همزمان می کند؛ روش هایی که تحت عناوین Black Hat GEO شناخته می شوند و شامل [...]

مدیر2025-11-24T00:05:59+03:30اکتبر 29, 2025|0 Comments
چکیده مقاله: دنیای دیجیتال هر روز در حال تغییر است و کاربران دیگر مثل گذشته به دنبال کلیک روی ده ها لینک نیستند. آن ها پاسخ را می خواهند، آن هم سریع، دقیق و [...]

مدیر2025-11-24T00:03:50+03:30اکتبر 28, 2025|0 Comments
چکیده مقاله: بهینه سازی موتور مولد (GEO) یکی از رویکردهای نوین در حوزه بهبود عملکرد سیستم های تولید محتوا و مدل های زبانی است که با هدف افزایش کیفیت، دقت و کارایی خروجی های [...]