
شبکه عصبی پیشخور (FNN) چیست؟
 چیست؟")
- شبکه عصبی پیشخور چیست؟
- انواع دیگر شبکه های عصبی
- ساختار شبکه عصبی پیشخور
- توابع فعال سازی
- کاربردهای شبکه عصبی پیشخور
- نحوه عملکرد شبکه های عصبی پیشخور
- آموزش شبکه عصبی پیشخور
- نزول گرادیان (Gradient Descent)
- ارزیابی شبکه عصبی پیشخور
- پیاده سازی کد شبکه عصبی پیشخور
- چه کسانی از شبکه های عصبی پیشخور استفاده می کنند؟
- سوالات متداول شبکه عصبی پیشخور
چکیده مقاله:
قبل از پرداختن به شبکه عصبی پیشخور (Feedforward Neural Network یا FNN) بهتر است بدانید که شبکه های عصبی مصنوعی (Artificial Neural Networks یا ANNs) تحول بزرگی در حوزه یادگیری ماشین ایجاد کرده اند و ابزارهای قدرتمندی برای تشخیص الگو، طبقه بندی و مدل سازی پیش بینی ارائه داده اند. در میان انواع مختلف شبکه های عصبی، شبکه عصبی پیشخور یکی از بنیادی ترین و پرکاربردترین ها است. در این مطلب، ساختار، عملکرد و کاربردهای شبکه های عصبی پیشخور بررسی می شود تا درک جامعی از این مدل ضروری یادگیری ماشین فراهم گردد.
شبکه عصبی پیشخور چیست؟
در میان انواع مختلف شبکه های عصبی یا سیستم های هوش مصنوعی که به کامپیوترها امکان پردازش داده ها را مشابه مغز انسان می دهند، شبکه های عصبی پیشخور (Feedforward Neural Networks) ساده ترین و در عین حال رایج ترین نوع هستند. شبکه های عصبی ابزاری برای یادگیری عمیق هستند که به عامل هوش مصنوعی امکان می دهند از تجربه و آموزش برای تعیین بهترین روش انجام یک وظیفه یاد بگیرد.
شبکه عصبی پیشخور نوعی شبکه عصبی مصنوعی است که اتصالات بین نودها در آن چرخه ای ایجاد نمی کند. این ویژگی، آن را از شبکه های عصبی بازگشتی (Recurrent Neural Networks یا RNNs) متمایز می کند. این شبکه از سه بخش تشکیل می شود: لایه ورودی، یک یا چند لایه مخفی و لایه خروجی. اطلاعات در این شبکه فقط در یک جهت، از ورودی به خروجی جریان دارد و به همین دلیل به آن “پیشخور” گفته می شود.
از منظر فنی، یک شبکه عصبی از مجموعه ای از گره ها (Nodes) تشکیل شده که در لایه های به هم متصل سازماندهی شده اند و به آن ها وزن هایی اختصاص داده شده است. هنگامی که داده به شبکه اضافه می شود، این داده از لایه های مخفی داخلی عبور کرده و خروجی تولید می کند. در شبکه عصبی پیشخور، داده به صورت پیوسته از طریق لایه ها عبور کرده و از ورودی به خروجی می رود، بدون اینکه به لایه های قبلی بازگردد.
نحوه حرکت داده ها در معماری شبکه، شبکه های عصبی پیشخور را تعریف می کند. هر شبکه عصبی با یک ورودی شروع شده و به یک خروجی ختم می شود. بین این دو مرحله، شبکه عصبی شامل لایه های مخفی است که کاربر آن ها را نمی بیند. این لایه های مخفی ساختاری را فراهم می کنند که بر اساس آن شبکه عصبی با داده ها تعامل می کند.
در عین حال، ماهیت سیستم به هوش مصنوعی اجازه می دهد بدون دخالت انسانی نتیجه گیری کند.
در یک شبکه عصبی پیشخور، هر گره به گره لایه بعدی متصل می شود. داده به صورت مداوم از یک لایه به لایه دیگر جریان می یابد، بدون حلقه یا چرخه. این جریان مداوم داده به جلو، دلیلی است که به این شبکه ها نام پیشخور داده شده است.
انواع دیگر شبکه های عصبی
علاوه بر اینکه شبکه های عصبی پیشخور ساده ترین و رایج ترین نوع شبکه های عصبی هستند، نقطه شروعی برای انواع دیگر شبکه های عصبی نیز محسوب می شوند که شامل شبکه های عصبی کانولوشنی و بازگشتی می شوند:
- شبکه های عصبی کانولوشنی (Convolutional Neural Networks):
شبکه های عصبی کانولوشنی قابلیت های اضافه ای برای کار با تصاویر، گفتار و صوت دارند. این شبکه ها شامل لایه های کانولوشنی و لایه های تجمعی (Pooling) بین ورودی و خروجی هستند. این لایه ها به هوش مصنوعی امکان تشخیص ویژگی های مختلف تصاویر و ویدیوها را می دهند. هر لایه کانولوشنی اضافه به هوش مصنوعی کمک می کند الگوهای سطح بالاتر را درک کند. لایه تجمعی که پس از آن می آید، اطلاعات را به فرمت قابل استفاده تبدیل می کند. - شبکه های عصبی بازگشتی (Recurrent Neural Networks):
شبکه های عصبی بازگشتی قادر به استفاده از داده های سری زمانی و درک توالی رویدادها و داده ها هستند. برای مثال، این شبکه ها می توانند نوسانات بازار سهام را پیش بینی کرده یا بفهمند چگونه ترتیب خاص کلمات بر معنای آن ها تأثیر می گذارد. تفاوت دیگر شبکه های بازگشتی این است که می توانند خروجی را گرفته و دوباره آن را از طریق الگوریتم اجرا کنند، قابلیتی که در شبکه های عصبی پیشخور وجود ندارد.
انواع دیگر شبکه های عصبی شامل شبکه های دکانولوشنی، شبکه های مدولار و شبکه های مولد رقابتی (GANs) هستند. در این دسته بندی ها، شبکه های عصبی می توانند به زیرمجموعه های خاص تر تقسیم شوند. برای مثال، شبکه های بازگشتی می توانند شامل واحدهای بازگشتی دروازه ای (GRU) یا شبکه های حافظه بلند مدت (LSTM) باشند. در مورد شبکه های کانولوشنی، می توان از مدل VGG یا شبکه عصبی باقی مانده (ResNet) استفاده کرد.
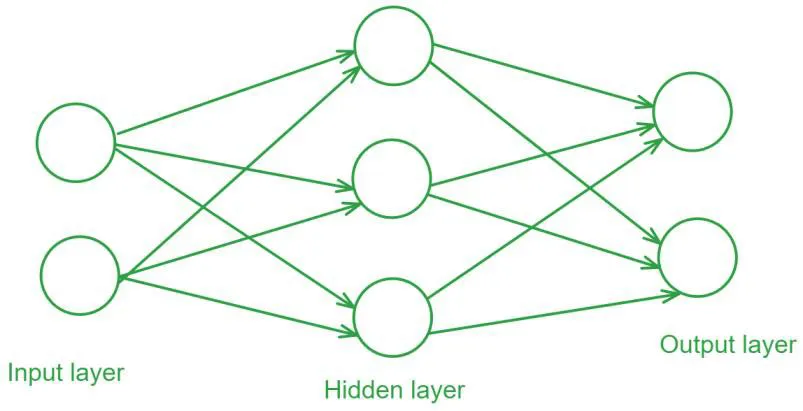
ساختار شبکه عصبی پیشخور
- لایه ورودی: لایه ورودی شامل نورون هایی است که داده های ورودی را دریافت می کنند. هر نورون در این لایه نماینده یک ویژگی از داده های ورودی است.
- لایه های مخفی: یک یا چند لایه مخفی بین لایه ورودی و لایه خروجی قرار دارند. این لایه ها مسئول یادگیری الگوهای پیچیده در داده ها هستند. هر نورون در لایه مخفی یک مجموع وزن دار از ورودی ها را محاسبه کرده و سپس یک تابع فعال سازی غیرخطی بر آن اعمال می کند.
- لایه خروجی: لایه خروجی خروجی نهایی شبکه را ارائه می دهد. تعداد نورون های این لایه برابر با تعداد کلاس ها در مسائل طبقه بندی یا تعداد خروجی ها در مسائل رگرسیون است.
هر اتصال بین نورون ها دارای یک وزن است که در فرآیند آموزش برای حداقل سازی خطای پیش بینی تنظیم می شود.
توابع فعال سازی
توابع فعال سازی غیرخطی بودن را به شبکه وارد می کنند و به آن امکان می دهند الگوهای پیچیده داده ها را بیاموزد و مدل سازی کند. توابع فعال سازی متداول عبارتند از:
- سیگموید:

- تانژانت هیپربولیک (Tanh):

- ReLU (واحد خطی اصلاح شده):

- Leaky ReLU (ReLU نشتی دار):

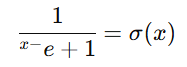
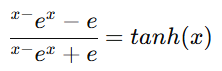
کاربردهای شبکه عصبی پیشخور
یکی از دلایل اصلی استفاده از شبکه های عصبی پیشخور توسط متخصصان علوم کامپیوتر، توانایی این شبکه ها در تقریب توابع است که شامل پیش بینی نحوه حل مسائل می شود. شبکه های پیشخور به پیشرفت های دیگر در هوش مصنوعی مانند بینایی کامپیوتر، پردازش زبان طبیعی، تشخیص الگو، تشخیص تصویر، پیش بینی سری های زمانی و وظایف طبقه بندی کمک می کنند.
بینایی کامپیوتر (Computer Vision)
این فناوری به هوش مصنوعی امکان پردازش داده های موجود در تصاویر یا ویدیوها را می دهد. به طور کلی، بینایی کامپیوتر به هوش مصنوعی این امکان را می دهد که «ببیند» و داده های بصری را از طریق تجربه داده های آموزشی خود فیلتر کرده و نتیجه گیری کند و تصمیم گیری کند. مهندسان شبکه عصبی معمولاً از شبکه های عصبی کانولوشنی برای توسعه بینایی کامپیوتر استفاده می کنند. چند نمونه از کاربردهای بینایی کامپیوتر عبارتند از:
- خودروهای خودران: وسایل نقلیه خودران از بینایی کامپیوتر برای درک نحوه حرکت در جاده استفاده می کنند.
- مدیریت محتوا: بینایی کامپیوتر، نیرو بخشیدن به عامل های هوش مصنوعی است که می توانند محتوای مضر را که به صورت آنلاین منتشر شده حذف کنند.
- تولید: بینایی کامپیوتر می تواند محصولات معیوب را قبل از خروج از کارخانه شناسایی کند.
- جستجوی تصویر: بینایی کامپیوتر جستجو در میان تصاویر بر اساس کلمات کلیدی موجود در تصویر را امکان پذیر می کند.
پردازش زبان طبیعی (Natural Language Processing)
بدون پردازش زبان طبیعی (NLP)، برای تعامل با کامپیوترها به زبان های برنامه نویسی نیاز داریم. اما با NLP، کامپیوترها و دستگاه های دیگر می توانند زبان انسانی را از طریق متن و گفتار درک کنند. چند نمونه از کاربردهای NLP عبارتند از:
- دستیارهای هوش مصنوعی: زمانی که با دستیار مجازی خود صحبت می کنید، پردازش زبان طبیعی امکان درک و پاسخگویی مناسب را فراهم می کند.
- عامل های مجازی: در هنگام بروز مشکل با یک فروشگاه یا شرکت آنلاین، اغلب می توانید با یک عامل مشتری مجازی آنلاین گفتگو کنید.
- تحلیل احساسات: پردازش زبان طبیعی به عامل هوش مصنوعی امکان درک لحن و احساس پشت پست های شبکه های اجتماعی را می دهد، و به برندها بینشی از عملکرد تلاش های بازاریابی خود می دهد.
- ترجمه زبان: ابزارهای آنلاین امکان ترجمه کلمات گفتاری یا نوشتاری به زبان دیگر را فراهم می کنند. پردازش زبان طبیعی این امکان را فراهم کرده و دقت آن را بسیار بیشتر از ترجمه های ماشینی قبلی کرده است.
پیش بینی سری های زمانی (Time Series Forecasting)
پیش بینی سری های زمانی فرآیند انجام پیش بینی برای آینده بر اساس آنچه در گذشته اتفاق افتاده است می باشد. از آنجا که شبکه های عصبی بازگشتی به داده های سری زمانی دسترسی دارند، آن ها به پیش بینی سری های زمانی کمک می کنند. چند کاربرد پیش بینی سری های زمانی عبارتند از:
- پیش بینی بازار سهام: موسسات مالی و سرمایه گذاران می توانند از شبکه های عصبی برای درک روندهای بازار سهام استفاده کرده و تصمیمات سرمایه گذاری را اطلاع رسانی کنند.
- پیش بینی آب و هوا: شبکه های عصبی می توانند به هواشناسان درک الگوهای آب و هوایی و اطلاع رسانی به جامعه درباره انتظارات کمک کنند.
- فصلی بودن در فروشگاه ها: بسیاری از شرکت ها، مانند فروشگاه ها و رستوران ها، فروش آن ها به صورت فصلی نوسان دارد. پیش بینی سری های زمانی به این شرکت ها کمک می کند که بفهمند چگونه فروش در طول سال نوسان می کند.
نحوه عملکرد شبکه های عصبی پیشخور
برای درک عملکرد شبکه های عصبی پیشخور، آشنایی با معماری آن ها می تواند مفید باشد. معماری شبکه عصبی پیشخور ساختار الگوریتم را شامل تعداد گره ها و لایه ها در شبکه مشخص می کند. در ساده ترین نوع شبکه عصبی پیشخور، یک لایه ورودی، یک لایه مخفی با تعدادی گره، و یک لایه خروجی وجود دارد. افزودن لایه های بیشتر می تواند توانایی شبکه را در درک و ارتباط با داده های ورودی افزایش دهد.
مطلب پیشنهادی: الگوریتم خفاش (Bat Algorithm) چیست؟
شبکه های عصبی از ساختار مغز انسان الهام گرفته شده اند و می توانند از تجربه خود یاد بگیرند و بر اساس داده های موجود تصمیم گیری کنند. ممکن است این سوال پیش بیاید که اگر داده ها به طور مداوم از یک شبکه عصبی پیشخور عبور می کنند، الگوریتم یادگیری عمیق چگونه در واقع یاد می گیرد؟
پاسخ این سوال در الگوریتم پس انتشار خطا (Backpropagation) نهفته است. این الگوریتم، یادگیری نظارت شده را شبیه سازی می کند و خروجی را از چندین لایه شبکه عصبی پیشخور عبور می دهد. الگوریتم، خروجی را ایجاد کرده و خطای بین پیش بینی و نتیجه واقعی را محاسبه می کند. در پاسخ به این خطا، وزن های الگوریتم تنظیم می شوند تا پیش بینی های دقیق تری در آینده ارائه دهد.
آموزش شبکه عصبی پیشخور
آموزش یک شبکه عصبی پیشخور شامل تنظیم وزن های نورون ها برای حداقل سازی خطا بین خروجی پیش بینی شده و خروجی واقعی است. این فرآیند معمولاً از طریق پس انتشار و نزول گرادیان انجام می شود:
- پیش انتشار: در پیش انتشار، داده های ورودی از شبکه عبور کرده و خروجی محاسبه می شود.
- محاسبه خطا: خطا (یا هزینه) با استفاده از یک تابع هزینه مانند میانگین مربعات خطا (MSE) برای وظایف رگرسیون یا آنتروپی متقاطع برای وظایف طبقه بندی محاسبه می شود.
- پس انتشار: در پس انتشار، خطا به شبکه بازگردانده شده و وزن ها با استفاده از گرادیان تابع هزینه به روزرسانی می شوند.
نزول گرادیان (Gradient Descent)
نزول گرادیان یک الگوریتم بهینه سازی است که با به روزرسانی وزن ها در جهت گرادیان منفی تابع هزینه، آن را به حداقل می رساند. انواع رایج نزول گرادیان شامل موارد زیر است:
- نزول گرادیان دسته ای: وزن ها پس از محاسبه گرادیان روی کل داده ها به روزرسانی می شوند.
- نزول گرادیان تصادفی (SGD): وزن ها برای هر نمونه آموزشی به صورت جداگانه به روزرسانی می شوند.
- نزول گرادیان مینی-بچ: وزن ها پس از محاسبه گرادیان روی یک دسته کوچک از نمونه های آموزشی به روزرسانی می شوند.
ارزیابی شبکه عصبی پیشخور
ارزیابی عملکرد مدل آموزش دیده شامل چندین معیار است:
- دقت (Accuracy): نسبت نمونه های به درستی طبقه بندی شده به کل نمونه ها.
- دقت پیش بینی (Precision): نسبت پیش بینی های مثبت درست به کل پیش بینی های مثبت.
- بازخوانی (Recall): نسبت پیش بینی های مثبت درست به کل نمونه های مثبت واقعی.
- امتیاز F1: میانگین هارمونیک دقت پیش بینی و بازخوانی، که توازنی میان این دو فراهم می کند.
- ماتریس سردرگمی (Confusion Matrix): جدولی برای توصیف عملکرد مدل طبقه بندی، شامل مثبت های درست، منفی های درست، مثبت های کاذب و منفی های کاذب.
مطلب پیشنهادی: الگوریتم کرم شب تاب چیست؟
پیاده سازی کد شبکه عصبی پیشخور
این کد فرآیند ساخت، آموزش و ارزیابی یک مدل شبکه عصبی برای طبقه بندی ارقام دست نوشته در مجموعه داده MNIST را نشان می دهد. ابتدا مجموعه داده MNIST بارگذاری و نرمال سازی می شود، به طوری که مقادیر پیکسل ها به بازه [0, 1] مقیاس بندی شوند.
معماری مدل با استفاده از API ترتیبی (Sequential) تعریف می شود. این معماری شامل یک لایه Flatten برای تبدیل ورودی تصویری دوبعدی به یک آرایه یک بعدی، یک لایه Dense با 128 نورون و تابع فعال سازی ReLU، و یک لایه Dense نهایی با 10 نورون و تابع فعال سازی Softmax برای خروجی احتمالات هر کلاس است.
مطلب پیشنهادی: مسئله کوله پشتی چیست؟
مدل با استفاده از بهینه ساز Adam، تابع هزینه SparseCategoricalCrossentropy و معیار SparseCategoricalAccuracy کامپایل می شود. مدل به مدت 5 دوره روی داده های آموزشی آموزش داده می شود. در نهایت، عملکرد مدل روی مجموعه داده آزمایشی ارزیابی شده و دقت آزمایشی چاپ می شود.
خروجی
چه کسانی از شبکه های عصبی پیشخور استفاده می کنند؟
اگر قصد دارید در حوزه مرتبط با شبکه های عصبی پیشخور فعالیت کنید، سه عنوان شغلی ممکن در این زمینه شامل مهندس هوش مصنوعی یا یادگیری ماشین، پژوهشگر شبکه عصبی، و معمار یادگیری عمیق می شود.
بیایید هر یک از این مشاغل و میانگین درآمد پایه سالانه آن ها را بررسی کنیم:
مهندس هوش مصنوعی یا یادگیری ماشین
- میانگین درآمد سالانه (Glassdoor): 131,223 دلار
- پیش بینی رشد شغلی (2022 تا 2032): 23 درصد
- نیازمندی های تحصیلی: معمولاً نیاز به مدرک لیسانس در علوم کامپیوتر یا رشته های مرتبط دارد.
در این نقش، شما مسئول طراحی و ایجاد الگوریتم های هوش مصنوعی و مدل های یادگیری ماشین برای ساخت و آزمایش سیستم های هوش مصنوعی خواهید بود. این نقش معمولاً به عنوان عضوی از یک تیم بزرگتر برای ایجاد محصولات هوش مصنوعی یا یادگیری ماشین عمل می کند. وظایف شامل ایجاد الگوریتم های جدید، آزمایش مدل ها، انجام تحلیل ها، و مستندسازی است.
پژوهشگر یادگیری ماشین
- میانگین درآمد سالانه (Glassdoor): 149,263 دلار
- پیش بینی رشد شغلی (2022 تا 2032): 23 درصد
- نیازمندی های تحصیلی: معمولاً نیاز به مدرک کارشناسی ارشد در یادگیری ماشین، علوم کامپیوتر، رباتیک، یا رشته های مرتبط دارد.
به عنوان یک پژوهشگر یادگیری ماشین، شما روی ایجاد الگوریتم های جدید برای پیشبرد فناوری هوش مصنوعی کار خواهید کرد. این کار ممکن است شامل پیشرفت در زمینه ریاضیات مرتبط با هوش مصنوعی باشد. در این نقش، همکاری با متخصصان دیگر از جمله دانشمندان داده و مهندسان یادگیری ماشین ضروری است.
معمار یادگیری عمیق
- میانگین درآمد سالانه (Glassdoor): 134,814 دلار
- پیش بینی رشد شغلی (2022 تا 2032): 8 درصد
- نیازمندی های تحصیلی: معمولاً نیاز به مدرک لیسانس در علوم کامپیوتر یا رشته های مرتبط دارد.
در این نقش، شما مسئول طراحی، ساخت، و مقیاس بندی زیرساخت هوش مصنوعی سازمان خود خواهید بود. انتخاب و ارزیابی فناوری ها، ابزارها، و راه حل های مناسب برای رشد هوش مصنوعی شرکت شما از وظایف اصلی این شغل است. همچنین اطمینان از در نظر گرفتن جنبه های ایمنی و اخلاقی در تمامی تصمیمات هوش مصنوعی بخشی از مسئولیت های شما خواهد بود.
نتیجه گیری
شبکه های عصبی پیشخور از اجزای بنیادی در حوزه یادگیری ماشین هستند. با وجود سادگی، آن ها ابزارهای قدرتمندی برای وظایف مختلف، از جمله طبقه بندی و رگرسیون، ارائه می دهند. با درک معماری، توابع فعال سازی و فرآیند آموزش آن ها می توان به قابلیت ها و محدودیت های این شبکه ها پی برد. پیشرفت های مداوم در تکنیک های بهینه سازی و توابع فعال سازی، شبکه های پیشخور را کارآمدتر و موثرتر کرده و به توسعه گسترده هوش مصنوعی کمک کرده است.
سوالات متداول شبکه عصبی پیشخور
شبکه عصبی پیشخور چیست؟
شبکه عصبی پیشخور نوعی شبکه عصبی است که در آن اطلاعات تنها در یک جهت از لایه ورودی به لایه خروجی جریان می یابد و هیچ چرخه یا حلقه ای وجود ندارد.
شبکه عصبی پیشخور چگونه کار می کند؟
در شبکه عصبی پیشخور، داده ها از میان چند لایه عبور می کنند:
- لایه ورودی: داده اولیه را دریافت می کند.
- لایه های مخفی: داده ها را که از لایه ورودی دریافت شده پردازش می کنند. این لایه ها شامل یک یا چند لایه هستند که نورون های آن ها توابع فعال سازی را بر ورودی ها اعمال می کنند.
- لایه خروجی: خروجی نهایی را تولید می کند.
جریان داده ها تنها در یک جهت، از لایه ورودی به لایه خروجی، بدون حلقه های بازخوردی صورت می گیرد.
توابع فعال سازی چیستند؟
توابع فعال سازی معادلات ریاضی هستند که خروجی نودهای یک شبکه عصبی را تعیین می کنند. این توابع خواص غیرخطی به شبکه اضافه می کنند و امکان یادگیری الگوهای پیچیده را فراهم می آورند. توابع فعال سازی متداول شامل ReLU، سیگموید و تانژانت هیپربولیک هستند.
نقش تابع هزینه چیست؟
تابع هزینه میزان تطابق پیش بینی های شبکه عصبی با مقادیر هدف واقعی را اندازه گیری می کند. این تابع یکی از اجزای حیاتی در آموزش شبکه های عصبی است، زیرا معیاری کمی برای هدایت فرآیند بهینه سازی فراهم می کند. توابع هزینه متداول شامل میانگین مربعات خطا (MSE) برای وظایف رگرسیون و آنتروپی متقاطع برای وظایف طبقه بندی هستند.
پس انتشار چیست؟
پس انتشار الگوریتمی است که برای آموزش شبکه های عصبی پیشخور استفاده می شود. این الگوریتم شامل محاسبه گرادیان تابع هزینه نسبت به هر وزن با استفاده از قانون زنجیره ای و سپس به روزرسانی وزن ها برای حداقل کردن هزینه با استفاده از یک الگوریتم بهینه سازی مانند نزول گرادیان یا Adam می باشد.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]