
شبکه عصبی بازگشتی (RNN) چیست؟
 چیست؟")
- شبکه عصبی بازگشتی چیست؟
- اجزای کلیدی شبکه عصبی بازگشتی
- نحوه کار شبکه عصبی بازگشتی
- توابع فعال سازی متداول
- انواع شبکه های عصبی بازگشتی
- انواع دیگر شبکه های عصبی بازگشتی
- معماری شبکه عصبی بازگشتی (RNN)
- فرآیند آموزش در شبکه های عصبی بازگشتی (RNN)
- مزایای شبکه های عصبی بازگشتی
- محدودیت های شبکه عصبی بازگشتی
- سوالات متداول درباره شبکه های عصبی بازگشتی
چکیده مقاله:
شبکه عصبی بازگشتی (RNN) در دهه 1980 توسط محققانی به نام های دیوید راملهارت، جفری هینتون و رونالد جی. ویلیامز معرفی شدند. RNN ها پایه گذار پیشرفت های مهمی در پردازش داده های ترتیبی مانند زبان طبیعی و تحلیل سری های زمانی بوده اند و همچنان بر تحقیقات و کاربردهای هوش مصنوعی تأثیر می گذارند. در این مقاله، به اصول اصلی RNN ها پرداخته، نحوه عملکرد آن ها را بررسی کرده و اهمیت آن ها را در وظایفی که ورودی های قبلی یک دنباله بر پیش بینی های آینده تأثیر می گذارند، توضیح خواهیم داد.
شبکه عصبی بازگشتی چیست؟
شبکه عصبی بازگشتی یا RNN یک شبکه عصبی عمیق است که بر روی داده های ترتیبی یا سری زمانی آموزش داده می شود تا یک مدل یادگیری ماشین (ML) ایجاد کند که بتواند پیش بینی ها یا نتایجی ترتیبی را بر اساس ورودی های ترتیبی ارائه دهد.
برای مثال، یک RNN ممکن است برای پیش بینی سطح روزانه سیل بر اساس داده های گذشته مربوط به سیل، جزر و مد و اطلاعات هواشناسی مورد استفاده قرار گیرد. اما RNN ها همچنین می توانند مسائل ترتیبی یا زمانی مانند ترجمه زبان، پردازش زبان طبیعی (NLP)، تحلیل احساسات، شناسایی گفتار و شرح تصاویر را نیز حل کنند.
در شبکه های عصبی سنتی، ورودی ها و خروجی ها به صورت مستقل از یکدیگر در نظر گرفته می شوند. اما وظایفی مانند پیش بینی کلمه بعدی در یک جمله نیازمند اطلاعات از کلمات قبلی است تا پیش بینی دقیق تری صورت گیرد. برای رفع این محدودیت، شبکه های عصبی بازگشتی (RNNs) توسعه یافتند.
شبکه های عصبی بازگشتی مکانیزمی را معرفی کرده اند که در آن خروجی یک گام به عنوان ورودی به گام بعدی بازگردانده می شود، و این امکان را فراهم می کند که اطلاعات ورودی های قبلی حفظ شوند. این طراحی RNN ها را برای وظایفی که زمینه و اطلاعات قبلی اهمیت دارند، مانند پیش بینی کلمه بعدی در یک جمله، بسیار مناسب می سازد.
ویژگی اصلی RNN ها حالت پنهان یا همان حافظه است که اطلاعات مهم ورودی های قبلی در دنباله را ذخیره می کند. با استفاده از همان پارامترها در تمام گام ها، RNN ها عملکردی یکپارچه بر روی ورودی ها دارند و پیچیدگی پارامترها را نسبت به شبکه های عصبی سنتی کاهش می دهند. این توانایی باعث شده است که RNN ها برای وظایف ترتیبی بسیار کارآمد باشند.
به زبان ساده، RNN ها همان شبکه را به هر عنصر در یک دنباله اعمال می کنند و با حفظ و انتقال اطلاعات مرتبط، می توانند وابستگی های زمانی را یاد بگیرند که شبکه های عصبی معمولی قادر به آن نیستند.
اجزای کلیدی شبکه عصبی بازگشتی
- نورون های بازگشتی
واحد پردازش اصلی در یک شبکه عصبی بازگشتی، واحد بازگشتی است که به صورت مستقیم به آن “نورون بازگشتی” گفته نمی شود. واحدهای بازگشتی حالتی پنهان را نگه می دارند که اطلاعات مربوط به ورودی های قبلی در یک دنباله را حفظ می کند. این واحدها با بازخورد دادن حالت پنهان خود، قادر به “یادآوری” اطلاعات از گام های قبلی و ثبت وابستگی های زمانی هستند. - بازگشایی RNN
بازگشایی یا “باز کردن” RNN فرایندی است که ساختار بازگشتی را در طول گام های زمانی گسترش می دهد. در طی بازگشایی، هر گام از دنباله به عنوان یک لایه جداگانه در سری نمایش داده می شود و نشان می دهد که چگونه اطلاعات در هر گام زمانی جریان می یابد. این بازگشایی امکان پس انتشار خطا در طول زمان (BPTT) را فراهم می کند؛ یک فرایند یادگیری که خطاها را در طول گام های زمانی انتشار می دهد تا وزن های شبکه تنظیم شده و توانایی RNN برای یادگیری وابستگی ها در داده های ترتیبی بهبود یابد.
نحوه کار شبکه عصبی بازگشتی
مشابه شبکه های عصبی سنتی مانند شبکه های عصبی پیش خور و شبکه های عصبی کانولوشنی (CNN)، شبکه های عصبی بازگشتی از داده های آموزشی برای یادگیری استفاده می کنند. وجه تمایز آن ها حافظه شان است، زیرا اطلاعات ورودی های قبلی را دریافت کرده و بر ورودی و خروجی فعلی تاثیر می گذارند.
در حالی که شبکه های یادگیری عمیق سنتی فرض می کنند که ورودی ها و خروجی ها مستقل از یکدیگر هستند، خروجی شبکه های عصبی بازگشتی به عناصر قبلی در دنباله بستگی دارد. اگرچه رویدادهای آینده نیز می توانند برای تعیین خروجی یک دنباله مفید باشند، شبکه های بازگشتی یک طرفه نمی توانند این رویدادها را در پیش بینی های خود در نظر بگیرند.
برای توضیح بهتر، به یک اصطلاح مثل “حال بد داشتن” توجه کنید که معمولاً برای توصیف بیماری یک فرد استفاده می شود. برای اینکه این اصطلاح معنی داشته باشد، باید به ترتیب خاصی بیان شود. به همین دلیل، شبکه های بازگشتی نیاز دارند که ترتیب هر کلمه در این اصطلاح را در نظر بگیرند و از آن اطلاعات برای پیش بینی کلمه بعدی در دنباله استفاده کنند.
هر کلمه در عبارت “حال بد داشتن” بخشی از یک دنباله است که ترتیب آن اهمیت دارد. RNN با حفظ یک وضعیت مخفی در هر مرحله زمانی، زمینه را دنبال می کند. یک حلقه بازخورد با انتقال وضعیت مخفی از یک مرحله زمانی به مرحله بعدی ایجاد می شود. این وضعیت مخفی به عنوان حافظه ای عمل می کند که اطلاعات مربوط به ورودی های قبلی را ذخیره می کند. در هر مرحله زمانی، RNN ورودی فعلی (برای مثال یک کلمه در جمله) را همراه با وضعیت مخفی از مرحله قبلی پردازش می کند. این فرآیند به RNN اجازه می دهد که داده های قبلی را “به یاد داشته باشد” و از آن اطلاعات برای تاثیرگذاری بر خروجی فعلی استفاده کند.
ویژگی دیگر شبکه های بازگشتی این است که آن ها پارامترها را در لایه های مختلف شبکه به اشتراک می گذارند. در حالی که شبکه های پیش خور وزن های متفاوتی در هر گره دارند، شبکه های عصبی بازگشتی یک پارامتر وزن مشترک در هر لایه شبکه دارند. البته این وزن ها از طریق فرآیندهای پس انتشار خطا و گرادیان نزولی تنظیم می شوند تا یادگیری تقویتی را تسهیل کنند.
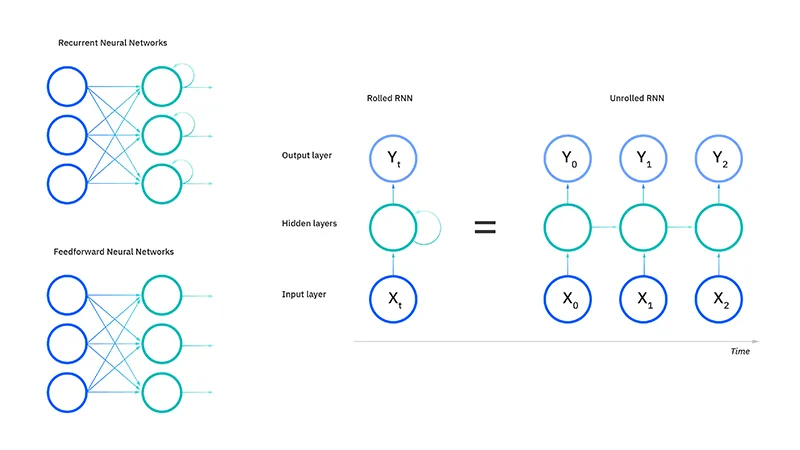
شبکه های عصبی بازگشتی از الگوریتم های انتشار رو به جلو و انتشار بازگشتی خطا در طول زمان (BPTT) برای تعیین گرادیان ها (یا مشتقات) استفاده می کنند، که این روش کمی متفاوت از انتشار خطای سنتی است و مخصوص داده های ترتیبی می باشد. اصول BPTT مشابه انتشار خطای سنتی است، جایی که مدل با محاسبه خطاها از لایه خروجی به لایه ورودی خود را آموزش می دهد. این محاسبات به ما اجازه می دهد که پارامترهای مدل را به طور مناسب تنظیم کنیم. تفاوت BPTT با روش سنتی در این است که BPTT خطاها را در هر مرحله زمانی جمع می کند، در حالی که شبکه های پیش خور به دلیل عدم اشتراک پارامترها نیازی به این جمع ندارند.
توابع فعال سازی متداول
یک تابع فعال سازی، تابعی ریاضی است که به خروجی هر لایه از نورون های شبکه اعمال می شود تا غیرخطی بودن را معرفی کند و امکان یادگیری الگوهای پیچیده تر را فراهم آورد. بدون توابع فعال سازی، شبکه عصبی بازگشتی فقط تبدیلات خطی ورودی را محاسبه می کند و در نتیجه قادر به پردازش مسائل غیرخطی نخواهد بود. غیرخطی بودن برای یادگیری و مدل سازی الگوهای پیچیده، به ویژه در وظایفی مثل NLP، تحلیل سری زمانی و پیش بینی داده های ترتیبی، ضروری است.
تابع فعال سازی، میزان خروجی نورون را کنترل می کند و مقادیر را در یک بازه مشخص (برای مثال، بین 0 و 1 یا -1 و 1) نگه می دارد، که این امر از بزرگ یا کوچک شدن بیش از حد مقادیر در طول مراحل پیشرو و پسرو جلوگیری می کند. در RNN ها، توابع فعال سازی در هر مرحله زمانی به وضعیت های مخفی اعمال می شوند و کنترل می کنند که چگونه شبکه حافظه داخلی (وضعیت مخفی) خود را بر اساس ورودی فعلی و وضعیت مخفی قبلی به روز رسانی کند.
توابع فعال سازی متداول شامل موارد زیر هستند:
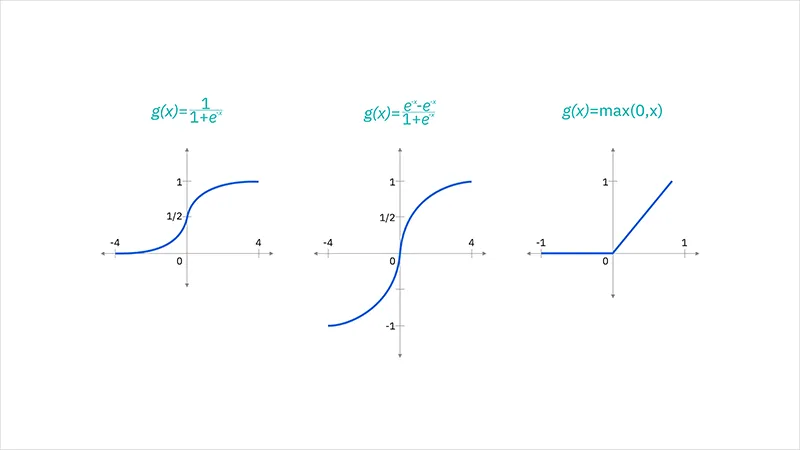
- تابع سیگموید: برای تفسیر خروجی به عنوان احتمال یا کنترل دروازه هایی که تعیین می کنند چه مقدار اطلاعات حفظ یا فراموش شوند. با این حال، این تابع نسبت به مشکل گرادیان ناپدیدشونده حساس است که آن را برای شبکه های عمیق تر کمتر مناسب می سازد.
- تابع تانژانت هیپربولیک (Tanh): اغلب مورد استفاده قرار می گیرد زیرا مقادیر خروجی آن حول صفر متمرکز است که این امر به جریان بهتر گرادیان و یادگیری آسان تر وابستگی های بلندمدت کمک می کند.
- ReLU (واحد خطی اصلاح شده): ممکن است به دلیل طبیعت نامحدود خود مشکلاتی با گرادیان های انفجاری ایجاد کند. با این حال، نسخه های متغیر مانند ReLU نشتی و ReLU پارامتریک برای کاهش برخی از این مشکلات مورد استفاده قرار گرفته اند.
انواع شبکه های عصبی بازگشتی
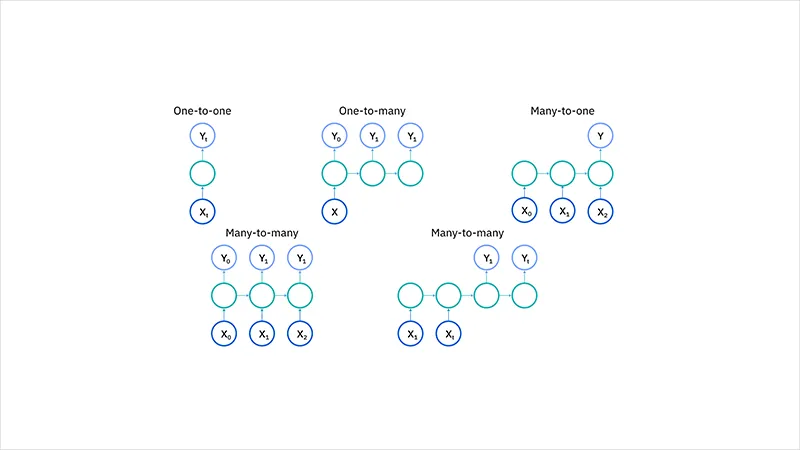
چهار نوع اصلی از شبکه های عصبی بازگشتی بر اساس تعداد ورودی ها و خروجی ها در شبکه وجود دارد:
RNN یک به یک
RNN یک به یک شبیه شبکه عصبی وانیلا (ساده ترین نوع معماری شبکه عصبی) عمل می کند. در این نوع، یک ورودی و یک خروجی وجود دارد. این ساختار به طور معمول برای وظایف طبقه بندی ساده استفاده می شود که در آن نقاط داده ورودی به عناصر قبلی وابسته نیستند.
RNN یک به چند
در RNN یک به چند، شبکه یک ورودی واحد را پردازش می کند و چندین خروجی را در طول زمان تولید می کند. این ساختار زمانی مفید است که یک عنصر ورودی واحد نیاز به تولید یک دنباله از پیش بینی ها داشته باشد.
به عنوان مثال، در وظیفه توصیف تصویر، مدل با یک تصویر به عنوان ورودی شروع کرده و دنباله ای از کلمات را به عنوان شرح تصویر پیش بینی می کند.
RNN چند به یک
RNN چند به یک یک دنباله از ورودی ها را دریافت می کند و یک خروجی واحد تولید می کند. این نوع زمانی کاربرد دارد که برای انجام یک پیش بینی واحد به کلیت دنباله ورودی نیاز باشد.
برای مثال، در تحلیل احساسات، مدل یک دنباله از کلمات (مانند یک جمله) را دریافت کرده و یک خروجی واحد تولید می کند که احساس جمله را تعیین می کند (مثبت، منفی یا خنثی).
RNN چند به چند
نوع RNN چند به چند یک دنباله از ورودی ها را پردازش کرده و یک دنباله از خروجی ها تولید می کند. این پیکربندی برای وظایفی که در آن دنباله های ورودی و خروجی باید در طول زمان هماهنگ باشند، ایده آل است. این هماهنگی می تواند به صورت یک به یک یا چند به چند باشد.
برای مثال، در وظیفه ترجمه زبان، یک دنباله از کلمات به زبان مبدا به عنوان ورودی داده می شود و دنباله ای متناظر به زبان مقصد به عنوان خروجی تولید می شود.
انواع دیگر شبکه های عصبی بازگشتی
شبکه های پیش خور ورودی ها و خروجی ها را به صورت یک به یک نگاشت می کنند. با این حال، اگرچه شبکه های عصبی بازگشتی را قبلاً در نمودارها به این صورت تصور کرده ایم، اما این محدودیت را ندارند. در عوض، ورودی ها و خروجی های آن ها می توانند طول های متفاوتی داشته باشند و انواع مختلفی از RNN ها برای کاربردهای متفاوت مانند تولید موسیقی، طبقه بندی احساسات و ترجمه زبان استفاده می شوند. انواع پرکاربرد معماری شبکه های عصبی بازگشتی عبارتند از:
- RNN های استاندارد
- شبکه های عصبی بازگشتی دوطرفه (BRNNs)
- حافظه بلند مدت کوتاه (LSTM)
- واحدهای بازگشتی گیت دار (GRUs)
- RNN های رمزگذار-رمزگشا (Encoder-Decoder)
RNN های استاندارد
نسخه پایه یک RNN که در آن خروجی در هر مرحله زمانی به هر دو ورودی فعلی و وضعیت مخفی مرحله زمانی قبلی وابسته است. این مدل ها با مشکلاتی مانند ناپدید شدن گرادیان مواجه هستند که یادگیری وابستگی های بلندمدت را برای آن ها دشوار می کند. این مدل ها در انجام وظایف ساده با وابستگی های کوتاه مدت، مانند پیش بینی کلمه بعدی در یک جمله کوتاه و ساده یا مقدار بعدی در یک سری زمانی ساده، عملکرد خوبی دارند.
RNN ها برای وظایفی که داده ها را به صورت ترتیبی در زمان واقعی پردازش می کنند، مناسب هستند. به عنوان مثال، پردازش داده های سنسور برای تشخیص ناهنجاری ها در بازه های زمانی کوتاه، جایی که ورودی ها به صورت یکی یکی دریافت شده و پیش بینی ها بلافاصله بر اساس ورودی های اخیر انجام می شوند.
شبکه های عصبی بازگشتی دوطرفه (BRNNs)
در حالی که RNN های یک طرفه فقط می توانند از ورودی های قبلی برای پیش بینی وضعیت فعلی استفاده کنند، RNN های دوطرفه یا BRNN ها، داده های آینده را نیز برای بهبود دقت استفاده می کنند. با بازگشت به مثال “حال بد داشتن”، یک مدل مبتنی بر BRNN می تواند بهتر پیش بینی کند که کلمه دوم این عبارت “بد” است اگر بداند کلمه آخر در دنباله “داشتن” می باشد.
حافظه بلند مدت کوتاه (LSTM)
LSTM یک معماری محبوب RNN است که توسط سپ هوخریتر و یورگن اشمیدهوبر معرفی شد تا مشکل گرادیان ناپدیدشونده را حل کند. این مدل به مشکل وابستگی های بلندمدت پرداخته است. به این معنا که اگر وضعیت قبلی که پیش بینی فعلی را تحت تأثیر قرار می دهد در گذشته نزدیک نباشد، مدل RNN ممکن است نتواند به درستی وضعیت فعلی را پیش بینی کند.
به عنوان مثال، فرض کنید می خواهیم کلمات مورب شده را در عبارت زیر پیش بینی کنیم:
“آلیس به آجیل حساسیت دارد. او نمی تواند کره بادام زمینی بخورد.”
زمینه مربوط به حساسیت به آجیل می تواند به ما کمک کند پیش بینی کنیم که غذایی که نمی توان خورد حاوی آجیل است. با این حال، اگر این زمینه چند جمله قبل بیان شده باشد، ممکن است مدل RNN نتواند این اطلاعات را به درستی مرتبط کند.
برای حل این مشکل، شبکه های LSTM در لایه های مخفی خود “سلول” هایی دارند که شامل سه گیت می باشند: یک گیت ورودی، یک گیت خروجی و یک گیت فراموشی. این گیت ها جریان اطلاعات مورد نیاز برای پیش بینی خروجی را در شبکه کنترل می کنند. به عنوان مثال، اگر ضمایر جنسیتی، مانند “او”، در جملات قبلی چندین بار تکرار شده باشد، ممکن است آن را از وضعیت سلول حذف کنید.
واحدهای بازگشتی گیت دار (GRUs)
GRU مشابه LSTM است و تلاش می کند مشکل حافظه کوتاه مدت مدل های RNN را حل کند. به جای استفاده از “وضعیت سلول” برای تنظیم اطلاعات، از وضعیت های مخفی استفاده می کند و به جای سه گیت، دارای دو گیت می باشد: یک گیت بازنشانی و یک گیت به روز رسانی. مشابه گیت های موجود در LSTM ها، گیت های بازنشانی و به روز رسانی میزان و نوع اطلاعاتی که باید نگهداری شود را کنترل می کنند.
به دلیل معماری ساده تر خود، GRU ها از نظر محاسباتی کارآمدتر هستند و به پارامترهای کمتری نیاز دارند در مقایسه با LSTM ها. این امر باعث می شود که آموزش آن ها سریع تر باشد و اغلب برای برخی کاربردهای زمان واقعی یا منابع محدود مناسب تر باشند.
RNN های رمزگذار-رمزگشا (Encoder-Decoder)
این مدل ها معمولاً برای وظایف تبدیل دنباله به دنباله مانند ترجمه زبان استفاده می شوند. رمزگذار دنباله ورودی را به یک بردار با طول ثابت (زمینه) تبدیل می کند و رمزگشا از آن زمینه برای تولید دنباله خروجی استفاده می کند. با این حال، بردار زمینه با طول ثابت می تواند به یک گلوگاه تبدیل شود، به ویژه برای دنباله های ورودی بلند.
معماری شبکه عصبی بازگشتی (RNN)
شبکه های عصبی بازگشتی (RNN) در ساختار ورودی و خروجی شباهت هایی با دیگر معماری های یادگیری عمیق دارند، اما در نحوه جریان اطلاعات از ورودی به خروجی تفاوت های قابل توجهی دارند. برخلاف شبکه های عصبی عمیق سنتی که هر لایه متراکم دارای ماتریس وزن مجزا می باشد، در RNN ها وزن ها در تمام گام های زمانی به اشتراک گذاشته می شوند و این امکان را فراهم می کنند که اطلاعات در طول دنباله ها حفظ شوند.
در RNN ها، حالت پنهان Hi برای هر ورودی Xi محاسبه می شود تا وابستگی های دنباله ای حفظ شوند. محاسبات بر اساس فرمول های اصلی زیر انجام می شوند:
محاسبه حالت پنهان:
![]()
- h: حالت پنهان فعلی
- U و W: ماتریس های وزن
- B: بایاس
- σ: تابع فعال سازی
محاسبه خروجی:
![]()
- Y: خروجی
- O: تابع فعال سازی
- V: ماتریس وزن
- C: بایاس
عملکرد کلی:
![]()
این فرمول عملکرد کلی RNN را تعریف می کند، جایی که ماتریس حالت SSS شامل هر عنصر sis_isi می باشد که نمایانگر وضعیت شبکه در هر گام زمانی iii است.
پارامترهای کلیدی در RNN:
- ماتریس های وزن: V , U , W
- بایاس ها: B , C
این پارامترها در تمام گام های زمانی ثابت می مانند و شبکه را قادر می سازند تا وابستگی های دنباله ای را با کارایی بیشتری مدل کند. این ویژگی برای وظایفی مانند پردازش زبان، پیش بینی سری های زمانی و موارد مشابه بسیار ضروری است.
فرآیند آموزش در شبکه های عصبی بازگشتی (RNN)
آموزش شبکه های عصبی بازگشتی شامل تغذیه داده های ورودی در طول چندین گام زمانی، ثبت وابستگی ها در این گام ها و به روزرسانی مدل از طریق پس انتشار خطا می باشد.
مراحل آموزش در RNN:
- ورودی در هر گام زمانی
یک گام زمانی از دنباله ورودی به شبکه ارائه می شود. - محاسبه حالت پنهان
شبکه با استفاده از ورودی فعلی و حالت پنهان قبلی، حالت پنهان فعلی ht را محاسبه می کند. - انتقال حالت
حالت پنهان فعلی ht به عنوان حالت پنهان قبلی ht-1 برای گام زمانی بعدی استفاده می شود. - پردازش ترتیبی
این فرآیند برای تمام گام های زمانی ادامه پیدا می کند تا اطلاعات از حالت های قبلی جمع آوری شود. - تولید خروجی و محاسبه خطا
از حالت پنهان نهایی برای محاسبه خروجی شبکه استفاده می شود. سپس این خروجی با مقدار هدف مقایسه شده و خطا محاسبه می شود. - پس انتشار خطا از طریق زمان (BPTT)
خطا به صورت معکوس از طریق هر گام زمانی انتشار داده می شود تا وزن ها به روزرسانی شوند و شبکه آموزش ببیند.
مزایای شبکه های عصبی بازگشتی
- حافظه ترتیبی
RNN ها اطلاعات ورودی های قبلی را حفظ می کنند، که این ویژگی برای پیش بینی های سری های زمانی که داده های گذشته اهمیت دارند ایده آل است. این قابلیت به طور خاص در معماری هایی مانند LSTM برجسته می باشد. - بهبود تحلیل همسایگی پیکسل ها
RNN ها در ترکیب با لایه های کانولوشنی می توانند همسایگی های گسترده تری از پیکسل ها را در داده های تصویری و ویدیویی ثبت کنند. این ویژگی باعث بهبود عملکرد در پردازش این نوع داده ها می شود.
کاربردهای شبکه های عصبی بازگشتی
شبکه های عصبی بازگشتی در موارد زیر که داده ها ترتیبی یا مبتنی بر زمان هستند استفاده می شوند:
- پیش بینی سری های زمانی
RNN ها در وظایف پیش بینی، مانند پیش بینی بازار سهام و پیش بینی آب و هوا، بسیار موثر هستند. - پردازش زبان طبیعی (NLP)
RNN ها در وظایف NLP مانند مدل سازی زبان، تحلیل احساسات و ترجمه ماشینی نقش اساسی دارند. - تشخیص گفتار
RNN ها الگوهای زمانی در داده های گفتاری را ثبت کرده و در برنامه هایی مانند تبدیل گفتار به متن و کاربردهای صوتی دیگر کمک می کنند. - پردازش تصویر و ویدیو
در ترکیب با لایه های کانولوشنی، RNN ها به تحلیل دنباله های ویدیویی، حالات چهره و تشخیص حرکات کمک می کنند.
محدودیت های شبکه عصبی بازگشتی
استفاده از RNN ها در هوش مصنوعی کاهش یافته است، به ویژه به دلیل ظهور معماری هایی مانند مدل های ترانسفورمر. با این حال، RNN ها هنوز منسوخ نشده اند. این شبکه ها به طور سنتی برای پردازش داده های ترتیبی (مانند سری های زمانی و مدل سازی زبان) محبوب بودند، زیرا توانایی مدیریت وابستگی های زمانی را داشتند.
با این وجود، ضعف RNN ها در مواجهه با مشکلات گرادیان ناپدیدشونده و انفجاری، همراه با ظهور مدل های ترانسفورمر مانند BERT و GPT، باعث کاهش محبوبیت آن ها شده است. مدل های ترانسفورمر توانایی بیشتری در درک وابستگی های بلندمدت دارند، به راحتی قابل موازی سازی هستند و در وظایفی مانند پردازش زبان طبیعی، تشخیص گفتار و پیش بینی سری های زمانی عملکرد بهتری ارائه می دهند.
با این حال، RNN ها هنوز در زمینه های خاصی که ماهیت ترتیبی و مکانیسم حافظه آن ها مفید است، مورد استفاده قرار می گیرند. به ویژه در محیط های کوچک و محدود از نظر منابع یا وظایفی که پردازش داده ها به صورت گام به گام مفید است، کاربرد دارند.
برای افرادی که می خواهند در این موارد خاص از RNN استفاده کنند، Keras یکی از کتابخانه های متن باز محبوب است که اکنون در کتابخانه TensorFlow ادغام شده است. این API یک رابط کاربری ساده و قابل تنظیم برای RNN ها در اختیار کاربران قرار می دهد، و آن ها می توانند لایه سلول RNN خود را با رفتار سفارشی تعریف کنند.
سوالات متداول درباره شبکه های عصبی بازگشتی
چه نوع مسائلی را می توان با RNN حل کرد؟
مدل سازی داده های وابسته به زمان و مسائل ترتیبی مانند تولید متن، ترجمه ماشینی و پیش بینی بازار سهام با شبکه های عصبی بازگشتی ممکن است. با این حال، مشکلاتی مانند کاهش گرادیان آموزش RNN را دشوار می کنند.
انواع RNN کدام اند؟
چهار نوع RNN عبارت اند از:
- یک به یک
- یک به چند
- چند به یک
- چند به چند
تفاوت های بین RNN و CNN چیست؟
تفاوت های کلیدی بین RNN و CNN به شرح زیر است:
- CNN ها معمولا در حل مسائل مرتبط با داده های فضایی مانند تصاویر استفاده می شوند.
- RNN ها برای تحلیل داده های متنی و ویدیویی که به صورت زمانی و ترتیبی سازماندهی شده اند بهتر عمل می کنند.
- معماری RNN ها و CNN ها از نظر طراحی با یکدیگر متفاوت است.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]