
درخت تصمیم چیست و چگونه استفاده می شود؟

چکیده مقاله :
در این مقاله می خواهیم بررسی کنیم که درخت تصمیم چیست ؟ درخت تصمیم یک الگوریتم یادگیری نظارت شده ناپارامتریک است که برای کارهای طبقه بندی و رگرسیون استفاده می شود. این ساختار درختی سلسله مراتبی دارد که از یک گره ریشه، شاخه ها، گره های داخلی و گره های برگ تشکیل شده است. شما با مطالعه این مطلب با مزایا و معایب درخت تصمیم ، مسائلی که در ان ها می توان از آن استفاده کرد ، نحوه استفاده و کاربرد ، ویژگی ها ، مفروضات با ذکر مثال به طور جامع آشنا می شوید.
1- درخت تصمیم (Decision Tree)
هزینه ها، فواید، احتمالات برای تحلیلگران داده (یا فقط انسان ها!) این مفاهیم کلید تصمیم گیری روزانه ما هستند. دقت کرده باشید، شما دائماً هر یک را وزن و مقایسه می کنید از تصمیم گیری برای خرید کدام مارک مواد شوینده تا بهترین برنامه اقدام برای کسب و کار شما. برای کسانی که در تجزیه و تحلیل داده ها و یادگیری ماشین کار می کنند، می توانیم این فرآیند تفکر را در الگوریتمی به نام “درخت تصمیم” رسم کنیم.
اما دقیقا درخت تصمیم چیست؟ این پست مقدمه ای کوتاه در مورد مفهوم درخت تصمیم، نحوه عملکرد آنها و نحوه استفاده از آنها برای مرتب کردن داده های پیچیده به روشی منطقی و بصری ارائه می دهد. خواه شما یک تحلیلگر داده تازه کار شده باشید یا فقط در مورد این زمینه کنجکاو باشید، در پایان این پست باید در موقعیت مناسبی قرار داشته باشید تا این مفهوم را با عمق بیشتری بررسی کنید.
جهت آشنایی بیشتر می توانید مقاله زیر را با عنوان تحلیل آماری چیست مطالعه نمایید.
2- درخت تصمیم چیست؟
در ساده ترین شکل آن، درخت تصمیم نوعی نمودار جریانی است که مسیر روشنی را برای تصمیم گیری نشان می دهد. از نظر تجزیه و تحلیل داده ها، این یک نوع الگوریتم است که شامل عبارات “کنترل” شرطی برای طبقه بندی داده ها است. درخت تصمیم از یک نقطه (یا «گره») شروع میشود که سپس در دو یا چند جهت منشعب میشود. هر شعبه نتایج ممکن متفاوتی را ارائه میکند، که شامل انواع تصمیمها و رویدادهای شانسی تا رسیدن به یک نتیجه نهایی است. هنگامی که به صورت بصری نشان داده می شود، ظاهر آنها مانند درخت است.
درخت های تصمیم برای تجزیه و تحلیل داده ها و یادگیری ماشین بسیار مفید هستند زیرا داده های پیچیده را به بخش های قابل مدیریت تر تجزیه می کنند. آنها اغلب در این زمینه ها برای تجزیه و تحلیل پیش بینی، طبقه بندی داده ها و رگرسیون استفاده می شوند. اگر همه اینها کمی انتزاعی به نظر می رسد نگران نباشید – ما در زیر چند مثال برای کمک به روشن شدن مسائل ارائه می دهیم. با این حال، ابتدا به جنبه های مختلفی که یک درخت تصمیم را می سازد نگاه می کنیم.
جهت آشنایی بیشتر می توانید مقاله زیر را با عنوان رگرسیون چیست مطالعه نمایید.
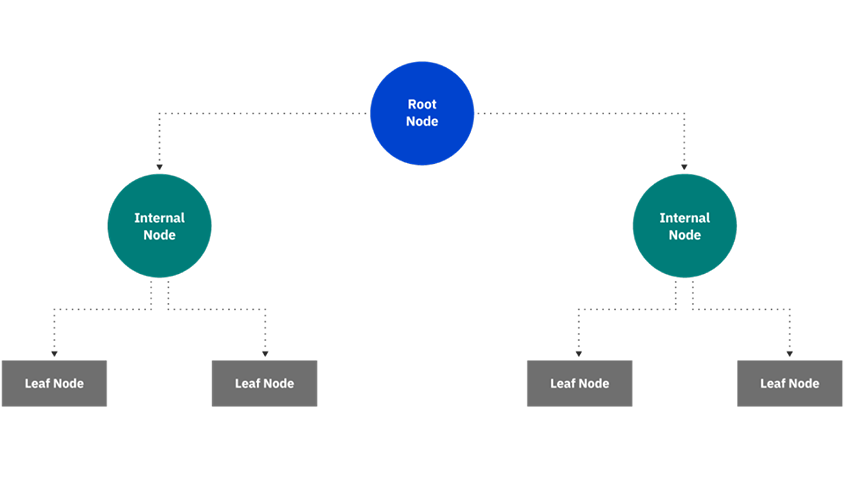
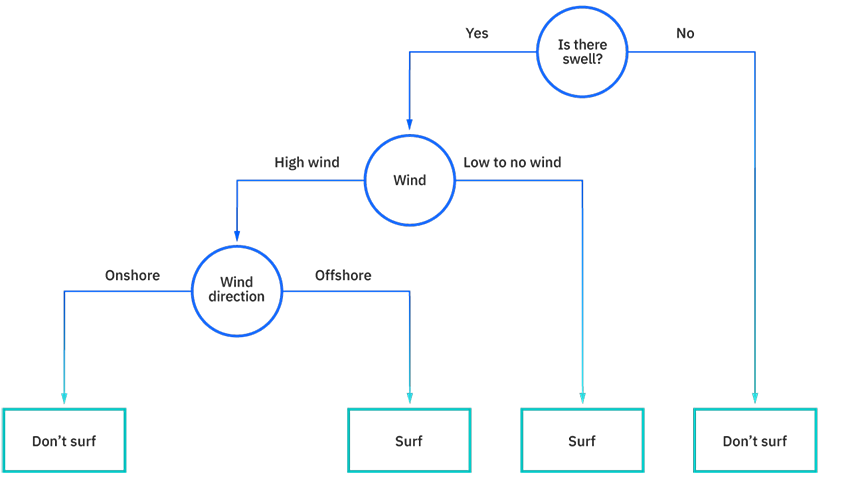
همانطور که از نمودار بالا می بینید، یک درخت تصمیم با یک گره ریشه شروع می شود که هیچ شاخه ورودی ندارد. سپس شاخه های خروجی از گره ریشه وارد گره های داخلی می شوند که به عنوان گره های تصمیم نیز شناخته می شوند. بر اساس ویژگیهای موجود، هر دو نوع گره ارزیابیهایی را برای تشکیل زیرمجموعههای همگن انجام میدهند که با گرههای برگ یا گرههای پایانی مشخص میشوند. گره های برگ همه نتایج ممکن را در مجموعه داده نشان می دهند. به عنوان مثال، بیایید تصور کنیم که سعی میکنید ارزیابی کنید که آیا باید موجسواری کنید یا نه، میتوانید از قوانین تصمیمگیری زیر برای انتخاب استفاده کنید:
این نوع ساختار نمودار جریان همچنین یک نمایش آسان برای هضم تصمیمگیری ایجاد میکند و به گروههای مختلف در سراسر یک سازمان اجازه میدهد تا درک بهتری از چرایی تصمیمگیری داشته باشند. در ادامه بخش های مختلف درخت تصمیم را معرفی می کنیم.
3- بخش های مختلف درخت تصمیم چیست؟
درختهای تصمیم میتوانند با دادههای پیچیده سروکار داشته باشند، که این مورد یک بخشی از آن چیزی است که آنها را مفید میکند. با این حال، این بدان معنا نیست که درک آنها دشوار است. در هسته خود، تمام درختان تصمیم در نهایت فقط از سه بخش کلیدی یا “گره” تشکیل شده اند:
• گره های تصمیم: نشان دهنده یک تصمیم (معمولا با مربع نشان داده می شود)
• گره های شانس: نشان دهنده احتمال یا عدم قطعیت (معمولاً با یک دایره مشخص می شود)
• گره های پایانی: نشان دهنده یک نتیجه (معمولاً با یک مثلث نشان داده شده است)
اتصال این گره های مختلف همان چیزی است که ما آن را “شاخه” می نامیم. گره ها و شاخه ها را می توان بارها و بارها در هر تعداد ترکیب برای ایجاد درختان با پیچیدگی های مختلف استفاده کرد. قبل از اینکه دادهای را اضافه کنیم، ببینیم این بخشها چگونه به نظر میرسند.
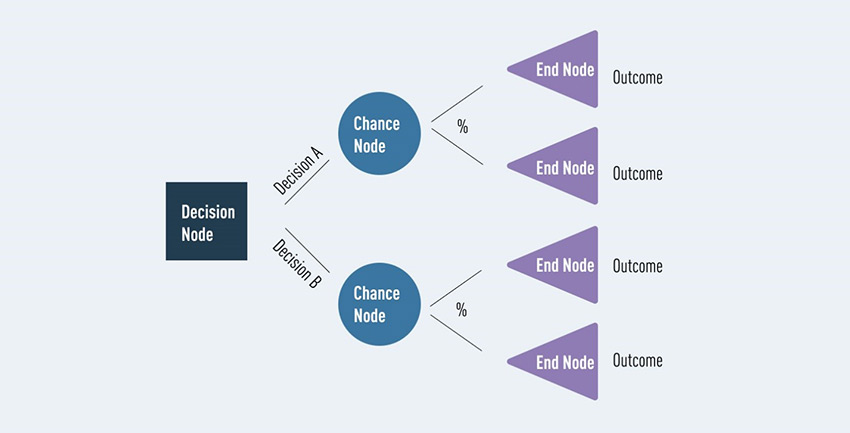
خوشبختانه، بسیاری از اصطلاحات درخت تصمیم از شکل بالا پیروی می کنند، که به خاطر سپردن آن را بسیار آسان می کند! برخی از اصطلاحات دیگری که ممکن است با آنها برخورد کنید عبارتند از:
1-3- گره های ریشه Root nodes
در نمودار بالا، گره تصمیم آبی چیزی است که ما آن را “گره ریشه” می نامیم. این گره همیشه اولین گره در مسیر است. این گره ای است که تمام گره های تصمیم، شانس و پایان دیگر در نهایت از آن منشعب می شوند.
2-3- گره های برگ Leaf nodes
در نمودار بالا، گره های انتهایی یاسی همان چیزی هستند که ما آن را “گره های برگ” می نامیم. این گره ها پایان یک مسیر تصمیم گیری (یا نتیجه) را نشان می دهند. شما همیشه میتوانید یک گره برگ را شناسایی کنید، زیرا دیگر منشعب نمیشود یا بیشتر منشعب نمیشود. درست مثل یک برگ واقعی!
3-3- گره های داخلی Leaf nodes
بین گره ریشه و گره برگ، می توانیم هر تعداد گره داخلی داشته باشیم. اینها می توانند شامل تصمیمات و گره های شانس باشند (برای سادگی، نمودار نشان داده شده فقط از گره های شانس استفاده می کند). شناسایی یک گره داخلی آسان است – هر کدام شاخه های مخصوص به خود را دارند و در عین حال به گره قبلی متصل می شوند.
4-3- تقسیم شدن Splitting
وقتی هر گره به دو یا چند گره فرعی تقسیم میشود، آن را انشعاب یا «تقسیم» مینامیم. این گرههای فرعی میتوانند گره داخلی دیگری باشند، یا میتوانند به یک نتیجه منجر شوند (گره برگ/پایان).
5-3- هرس Pruning
گاهی اوقات درختان تصمیم می توانند بسیار پیچیده رشد کنند. در این موارد، آنها می توانند به داده های نامربوط وزن زیادی بدهند. برای جلوگیری از این مشکل، میتوانیم گرههای خاصی را با استفاده از فرآیندی به نام «هرس» حذف کنیم. هرس دقیقاً همان چیزی است که به نظر می رسد – اگر درخت شاخه هایی را رشد دهد که ما به آنها نیاز نداریم، آنها را به سادگی قطع می کنیم.
4- نمونه ای از درخت تصمیم گیری ساده
با توجه به توضیحات داده شده ، یادگیری درخت تصمیم با انجام یک جستجوی حریصانه برای شناسایی نقاط تقسیم بهینه در یک درخت، از استراتژی تقسیم و غلبه استفاده می کند. سپس این فرآیند تقسیم به صورت بازگشتی از بالا به پایین تکرار می شود تا زمانی که همه یا اکثر رکوردها تحت برچسب های کلاس خاصی طبقه بندی شوند. اینکه آیا همه نقاط داده به عنوان مجموعه های همگن طبقه بندی می شوند یا نه، تا حد زیادی به پیچیدگی درخت تصمیم بستگی دارد. درختان کوچکتر راحت تر می توانند به گره های برگ خالص دست یابند.
درختان تصمیم برای درختان کوچک ترجیح دارند که با اصل صرفه جویی در Occam’s Razor سازگار است. یعنی «موجودات نباید بیش از ضرورت تکثیر شوند». به طور متفاوت، درختان تصمیم فقط در صورت لزوم باید پیچیدگی اضافه کنند، زیرا ساده ترین توضیح اغلب بهترین است. برای کاهش پیچیدگی و جلوگیری از برازش بیش از حد، معمولاً از هرس استفاده می شود. این فرآیندی است که شاخه هایی را که بر روی ویژگی هایی با اهمیت کم تقسیم می شوند حذف می کند. سپس برازش مدل را می توان از طریق فرآیند اعتبار سنجی متقابل ارزیابی کرد.
اکنون که اصول اولیه را پوشش دادیم، بیایید ببینیم درخت تصمیم چگونه ممکن است به نظر برسد. ما آن را واقعا ساده نگه خواهیم داشت. بیایید طبقه بندی کنیم که اگر گرسنه باشیم چه گزینه هایی در دسترس ما هستند. می توان این را به صورت زیر نشان دهیم:
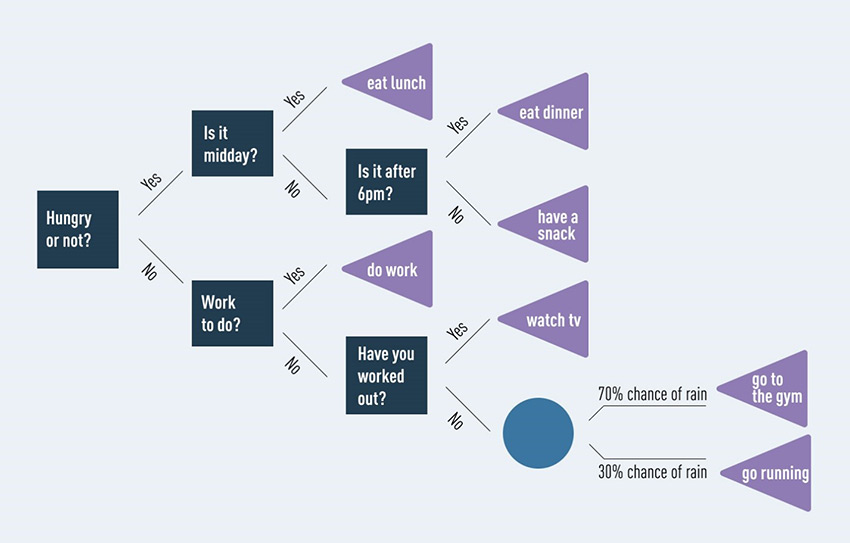
در این نمودار، گزینه های مختلف ما به روشی واضح و بصری نشان داده شده است. گره های تصمیم به رنگ آبی تیره، گره های شانس آبی روشن و گره های انتهایی بنفش هستند. درک و دیدن نتایج احتمالی برای هر کسی آسان است.
با این حال، فراموش نکنیم: هدف ما طبقه بندی کارهایی بود که در صورت گرسنگی انجام دهیم. با گنجاندن گزینه هایی برای انجام کارهایی که در صورت گرسنه نبودن انجام دهیم، درخت تصمیم خود را بیش از حد پیچیده کرده ایم. به هم ریختن درخت به این روش یک مشکل رایج است، به خصوص زمانی که با حجم زیادی از داده ها سروکار داریم. اغلب منجر به استخراج معنا از اطلاعات نامربوط توسط الگوریتم می شود. این موضوع به عنوان overfitting شناخته می شود. یکی از گزینههای اصلاح بیش از حد، هرس درخت است:
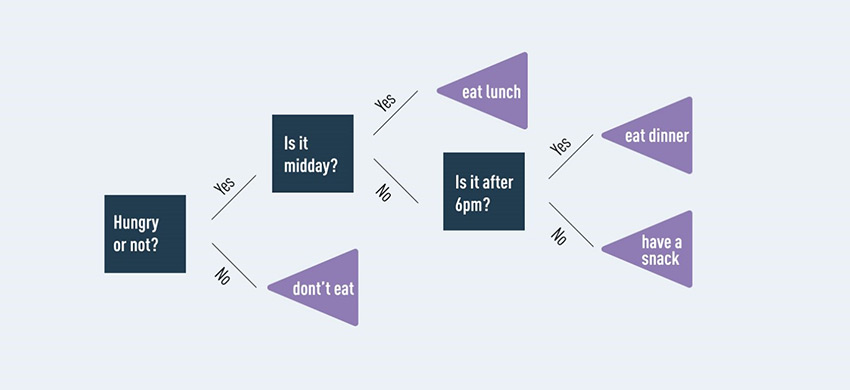
همانطور که می بینید، تمرکز درخت تصمیم ما اکنون بسیار واضح تر است. با حذف اطلاعات نامربوط (مثلاً اگر گرسنه نیستیم چه کنیم) نتایج ما بر هدفی متمرکز میشود که در نظر داریم. این نمونه ای از دامی است که درختان تصمیم می توانند در آن بیفتند و چگونه می توان از آن دور شد. با این حال، چندین مزایا و معایب برای درختان تصمیم وجود دارد. در ادامه به این موارد می پردازیم.
5- مزایا و معایب درخت تصمیم
درختان تصمیم با استفاده موثر، ابزار بسیار قدرتمندی هستند. با این وجود، مانند هر الگوریتمی، آنها برای هر موقعیتی مناسب نیستند. بااینکه درخت های تصمیم را می توان در موارد مختلف استفاده کرد، الگوریتم های دیگر معمولاً از الگوریتم های درخت تصمیم بهتر عمل می کنند. همانطور که گفته شد، درخت های تصمیم به ویژه برای داده کاوی و وظایف کشف دانش مفید هستند. بیایید مزایا و چالشهای کلیدی استفاده از درختهای تصمیم را در زیر بیشتر بررسی کنیم:
1-5- مزایای درخت تصمیم
• برای تفسیر داده ها به روشی بسیار بصری خوب است.
• برای مدیریت ترکیبی از داده های عددی و غیر عددی خوب است.
• تعریف آسان قوانین، به عنوان مثال. “بله، نه، اگر، پس، دیگر…”
• قبل از استفاده به حداقل آماده سازی یا تمیز کردن داده ها نیاز دارد.
• روشی عالی برای انتخاب بین بهترین، بدترین و محتمل ترین سناریوها.
• می توان به راحتی با سایر تکنیک های تصمیم گیری ترکیب کرد.
توضیح بیشتر
– تفسیر آسان: منطق بولی و نمایش بصری درختان تصمیم گیری، درک و استفاده آنها را آسان تر می کند. ماهیت سلسله مراتبی یک درخت تصمیم همچنین تشخیص اینکه کدام ویژگی ها مهم تر هستند را آسان می کند، که همیشه با الگوریتم های دیگر، مانند شبکه های عصبی، واضح نیست.
– نیاز به آماده سازی داده کم و یا بدون نیاز است: درخت های تصمیم دارای تعدادی ویژگی هستند که آن را نسبت به سایر طبقه بندی کننده ها انعطاف پذیرتر می کند. این می تواند انواع مختلف داده را مدیریت کند – به عنوان مثال. مقادیر گسسته یا پیوسته و مقادیر پیوسته را می توان با استفاده از آستانه ها به مقادیر مقوله ای تبدیل کرد. علاوه بر این، میتواند مقادیر با مقادیر گمشده را نیز مدیریت کند، که میتواند برای طبقهبندیکنندههای دیگر مانند Naïve Bayes مشکلساز باشد.
– انعطافپذیرتر: درختهای تصمیمگیری را میتوان برای کارهای طبقهبندی و رگرسیون به کار برد، که آن را نسبت به برخی الگوریتمهای دیگر انعطافپذیرتر میکند. همچنین نسبت به روابط اساسی بین صفات حساس نیست. این بدان معناست که اگر دو متغیر به شدت همبستگی داشته باشند، الگوریتم فقط یکی از ویژگیها را برای تقسیم کردن انتخاب میکند.
2-5- معایب درخت تصمیم
• تطبیق بیش از حد یا overfitting (که در آن مدل از داده های نامربوط معنا را تفسیر می کند) اگر طراحی درخت تصمیم خیلی پیچیده باشد، می تواند به مشکل تبدیل شود.
• آنها برای متغیرهای پیوسته مناسب نیستند (یعنی متغیرهایی که می توانند بیش از یک مقدار یا طیفی از مقادیر داشته باشند).
• در تجزیه و تحلیل پیش بینی، محاسبات می توانند به سرعت دست و پا گیر شوند، به خصوص زمانی که یک مسیر تصمیم گیری شامل متغیرهای شانس زیادی باشد.
• هنگام استفاده از یک مجموعه داده نامتعادل (یعنی جایی که یک دسته از داده ها بر دیگری غالب است) به راحتی می توان نتایج را به نفع کلاس غالب سوگیری کرد.
• به طور کلی، درخت های تصمیم در مقایسه با سایر الگوریتم های پیش بینی، دقت پیش بینی کمتری را ارائه می دهند.
توضیح بیشتر
– مستعد برازش بیش از حد : درختان تصمیم گیری پیچیده تمایل به برازش بیش از حد یا همان overfitting دارند و به خوبی به داده های جدید تعمیم نمی دهند.
– برآوردگرهای واریانس بالا: تغییرات کوچک در داده ها می تواند درخت تصمیم گیری بسیار متفاوتی ایجاد کند. بسته بندی یا میانگین گیری تخمین ها می تواند روشی برای کاهش واریانس درختان تصمیم باشد. با این حال، این رویکرد محدود است زیرا میتواند منجر به پیشبینیکنندههای بسیار همبسته شود.
– پرهزینه تر: با توجه به اینکه درختان تصمیم در طول ساخت و ساز رویکرد جستجوی حریصانه ای دارند، آموزش آنها در مقایسه با الگوریتم های دیگر گران تر است.
– به طور کامل در scikit-learn پشتیبانی نمی شود: Scikit-learn یک کتابخانه محبوب یادگیری ماشینی است که در پایتون قرار دارد. در حالی که این کتابخانه دارای یک ماژول درخت تصمیم است (DecisionTreeClassifier، پیوند خارج از ibm.com قرار دارد)، پیاده سازی فعلی از متغیرهای طبقه بندی پشتیبانی نمی کند.
6- درخت تصمیم برای چه مواردی استفاده می شود؟
درختان تصمیم با وجود معایبی که دارند، هنوز یک ابزار قدرتمند و محبوب هستند. آنها معمولاً توسط تحلیلگران داده برای انجام تجزیه و تحلیل پیش بینی کننده (به عنوان مثال برای توسعه استراتژی های عملیات در مشاغل) استفاده می شوند. آنها همچنین یک ابزار محبوب برای ماشین لرنینگ و هوش مصنوعی هستند، جایی که از آنها به عنوان الگوریتم های آموزشی برای یادگیری نظارت شده استفاده می شود (یعنی دسته بندی داده ها بر اساس تست های مختلف، مانند طبقه بندی کننده های “بله” یا “خیر”.)
به طور کلی، درختان تصمیم در طیف وسیعی از صنایع برای حل بسیاری از مشکلات استفاده می شوند. به دلیل انعطاف پذیری آنها، آنها در بخش هایی از فناوری و سلامت گرفته تا برنامه ریزی مالی استفاده می شوند. مثالها عبارتند از:
• یک تجارت فناوری که فرصت های توسعه را بر اساس تجزیه و تحلیل داده های فروش گذشته ارزیابی می کند.
• یک شرکت اسباببازی تصمیم میگیرد که بودجه تبلیغاتی محدود خود را کجا هدف قرار دهد، بر اساس آنچه که دادههای جمعیتی نشان میدهد که مشتریان احتمالاً خرید میکنند.
• بانکها و ارائهدهندگان وام مسکن از دادههای تاریخی برای پیشبینی میزان احتمال عدم پرداخت وامگیرنده در پرداختهای خود استفاده میکنند.
• تریاژ اتاق اورژانس ممکن است از درخت های تصمیم برای اولویت بندی مراقبت از بیمار استفاده کند (بر اساس عواملی مانند سن، جنسیت، علائم و غیره)
• سیستم های تلفن خودکار که شما را به نتیجه ای که نیاز دارید راهنمایی می کند، به عنوان مثال. برای گزینه A دکمه 1 را فشار دهید. برای گزینه B دکمه 2 را فشار دهید و غیره.
همانطور که می بینید، استفاده های زیادی برای درختان تصمیم وجود دارد!
7- درخت تصمیم و IBM
IBM SPSS Modeler یک ابزار داده کاوی است که به شما امکان می دهد مدل های پیش بینی را توسعه دهید تا آنها را در عملیات تجاری بکار ببرید. IBM SPSS Modeler که بر اساس مدل استاندارد صنعتی CRISP-DM طراحی شده است، از کل فرآیند داده کاوی، از پردازش داده تا نتایج کسب و کار بهتر، پشتیبانی می کند.
IBM SPSS Decision Trees دارای طبقه بندی بصری و درخت تصمیم است که به شما کمک می کند نتایج طبقه بندی شده را ارائه دهید و تجزیه و تحلیل را واضح تر برای مخاطبان غیر فنی توضیح دهید. ایجاد مدل های طبقه بندی برای تقسیم بندی، طبقه بندی، پیش بینی، کاهش داده ها و غربالگری متغیر.
8- جمع بندی
درک درختهای تصمیم ساده هستند و همچنان برای مجموعه دادههای پیچیده عالی هستند. این خصوصیت آنها را به ابزاری بسیار همه کاره تبدیل می کند. به طور خلاصه:
• درختان تصمیم از سه بخش اصلی تشکیل شده اند – گره های تصمیم (نشان دهنده انتخاب)، گره های شانس (نشان دهنده احتمال)، و گره های پایانی (نشان دهنده نتایج).
• درختان تصمیم را می توان برای مقابله با مجموعه داده های پیچیده استفاده کرد و در صورت لزوم می توان آنها را هرس کرد تا از برازش بیش از حد جلوگیری شود.
• علیرغم داشتن مزایای بسیار، درخت های تصمیم برای همه انواع داده ها مناسب نیستند، به عنوان مثال. متغیرهای پیوسته یا مجموعه داده های نامتعادل
• آنها در تجزیه و تحلیل داده ها و یادگیری ماشینی با کاربردهای عملی در بخش های مختلف از سلامت، مالی و فناوری محبوب هستند.
اکنون اصول اولیه را یاد گرفته اید، آماده هستید تا این الگوریتم همه کاره را با عمق بیشتری بررسی کنید. برخی از کاربردهای مفید درخت تصمیم را با جزئیات بیشتر در پست های آینده پوشش خواهیم داد.





مدیر2025-11-23T23:33:51+03:30نوامبر 23, 2025|0 Comments
هوش مصنوعی Grok یکی از جدیدترین و پیشرفته ترین ابزارهای هوش مصنوعی است که تجربه گفتگویی طبیعی و هوشمند را برای کاربران فراهم می کند. این سیستم نه تنها پاسخگوی سوالات روزمره است، بلکه [...]

مدیر2025-11-18T00:15:22+03:30نوامبر 18, 2025|0 Comments
هوش مصنوعی Gemini چیست؟ این سوال این روزها به یکی از پرجستجوترین موضوعات در فضای تکنولوژی تبدیل شده است، چون Gemini به عنوان پیشرفته ترین مدل هوش مصنوعی گوگل توانسته مرزهای پردازش زبان، تصویر، [...]

مدیر2025-11-07T00:34:24+03:30نوامبر 7, 2025|0 Comments
چکیده مقاله: E-E-A-T مخفف چهار واژهی Experience (تجربه)، Expertise (تخصص)، Authoritativeness (اعتبار) و Trustworthiness (قابلاعتماد بودن) است. این مفهوم توسط گوگل معرفی شده تا معیارهایی برای ارزیابی کیفیت محتوای وب سایت ها ارائه دهد. [...]

مدیر2025-11-06T00:58:39+03:30نوامبر 6, 2025|0 Comments
چکیده مقاله: GEO کلاه سیاه معبری است به دنیایی که وسوسه موفقیت سریع را با تکنیک های پرخطر همزمان می کند؛ روش هایی که تحت عناوین Black Hat GEO شناخته می شوند و شامل [...]

مدیر2025-11-24T00:05:59+03:30اکتبر 29, 2025|0 Comments
چکیده مقاله: دنیای دیجیتال هر روز در حال تغییر است و کاربران دیگر مثل گذشته به دنبال کلیک روی ده ها لینک نیستند. آن ها پاسخ را می خواهند، آن هم سریع، دقیق و [...]

مدیر2025-11-24T00:03:50+03:30اکتبر 28, 2025|0 Comments
چکیده مقاله: بهینه سازی موتور مولد (GEO) یکی از رویکردهای نوین در حوزه بهبود عملکرد سیستم های تولید محتوا و مدل های زبانی است که با هدف افزایش کیفیت، دقت و کارایی خروجی های [...]