
رگرسیون لجستیک (logistic regression) چیست؟
 چیست؟")
- رگرسیون لجستیک چیست؟
- اهمیت رگرسیون لجستیک چیست؟
- مزایای استفاده از رگرسیون لجستیک نسبت به دیگر تکنیکهای یادگیری ماشین
- کاربردهای رگرسیون لجستیک
- تحلیل رگرسیون چگونه کار میکند؟
- رگرسیون لجستیک چگونه کار میکند؟
- فرمول تابع رگرسیون لجستیک
- تفسیر رگرسیون لجستیک
- انواع تحلیل رگرسیون لجستیک
- رگرسیون لجستیک و ماشین لرنینگ
- مقایسه رگرسیون لجستیک با دیگر تکنیک های یادگیری ماشین
چکیده مقاله:
رگرسیون لجستیک احتمال وقوع یک رویداد، مانند رای دادن یا رای ندادن، را بر اساس یک مجموعه داده از متغیرهای مستقل تخمین میزند. این نوع مدل آماری (که به آن مدل لاجیت نیز گفته میشود) اغلب برای تحلیلهای دسته بندی و پیش بینی استفاده می شود. از آنجا که نتیجه یک احتمال است، متغیر وابسته بین ۰ و ۱ محدود می شود. در رگرسیون لجستیک، یک تبدیل لاجیت بر روی شانسها اعمال میشود؛ به عبارت دیگر، احتمال موفقیت تقسیم بر احتمال شکست. این نیز معمولاً به عنوان لاگ شانس یا لگاریتم طبیعی شانسها شناخته میشود. در این مطلب به بررسی کامل رگرسیون لجستیک می پردازیم.
رگرسیون لجستیک چیست؟
رگرسیون لجستیک یک تکنیک تحلیل داده است که با استفاده از ریاضیات، رابطه میان دو متغیر را شناسایی میکند و سپس بر اساس این رابطه، مقدار یکی از متغیرها را بر اساس دیگری پیش بینی میکند. معمولاً این پیش بینی شامل تعداد محدودی از نتایج ممکن، مانند “بله” یا “خیر” است.
برای مثال، فرض کنید میخواهید پیش بینی کنید که آیا بازدیدکننده وب سایت شما دکمه “پرداخت” را در سبد خرید خود کلیک میکند یا خیر. رگرسیون لجستیک، رفتارهای گذشته بازدیدکنندگان مانند مدت زمان حضور در وب سایت و تعداد آیتمهای موجود در سبد خرید را بررسی میکند. این روش به این نتیجه می رسد که اگر بازدیدکنندگان بیشتر از پنج دقیقه در سایت بمانند و بیش از سه آیتم در سبد خرید داشته باشند، احتمالاً دکمه پرداخت را کلیک میکنند. با استفاده از این اطلاعات، تابع رگرسیون لجستیک میتواند رفتار یک بازدیدکننده جدید را پیش بینی کند.
اهمیت رگرسیون لجستیک چیست؟
رگرسیون لجستیک یکی از تکنیکهای مهم در زمینه هوش مصنوعی و یادگیری ماشین (AI/ML) محسوب میشود. مدل های یادگیری ماشین برنامه های نرم افزاری هستند که میتوان آنها را آموزش داد تا بدون دخالت انسان، وظایف پیچیده پردازش داده را انجام دهند. مدل های یادگیری ماشین که با استفاده از رگرسیون لجستیک ساخته میشوند، به سازمانها کمک میکنند تا بینش های کاربردی از داده های کسب وکار خود کسب کنند. این بینش ها می توانند در تحلیل پیش بینی بهکار برده شوند تا هزینه های عملیاتی کاهش یابد، بهره وری افزایش یابد و رشد سریعتری محقق شود.
به عنوان مثال، کسب و کارها می توانند الگوهایی را شناسایی کنند که به حفظ کارکنان کمک میکند یا منجر به طراحی محصولاتی با سودآوری بیشتر میشود. با استفاده از رگرسیون لجستیک، سازمانها میتوانند رفتار مشتریان را پیشبینی کنند، احتمال ریسک مالی را ارزیابی کنند و حتی نیازهای آینده مشتریان را شناسایی کنند. همچنین، این تکنیک به شرکتها اجازه میدهد که با دقت بیشتری کمپینهای بازاریابی خود را بهینه سازی کنند و محصولات و خدمات خود را بر اساس تحلیل های دقیقتر به بازار عرضه کنند.
مزایای استفاده از رگرسیون لجستیک نسبت به دیگر تکنیکهای یادگیری ماشین
-
سادگی
مدلهای رگرسیون لجستیک از نظر ریاضی پیچیدگی کمتری نسبت به سایر روشهای یادگیری ماشین دارند. به همین دلیل، حتی اگر هیچکس در تیم شما تخصص عمیقی در یادگیری ماشین نداشته باشد، میتوانید این مدلها را پیادهسازی کنید. -
سرعت
مدلهای رگرسیون لجستیک به دلیل نیاز به توان محاسباتی کمتر (مانند حافظه و قدرت پردازش)، قادر به پردازش حجم زیادی از دادهها با سرعت بالا هستند. این ویژگی باعث میشود که این مدلها برای سازمانپ هایی که به تازگی در حال شروع پروژه های یادگیری ماشین هستند و به دنبال نتایج سریع هستند، بسیار مناسب باشند. -
انعطاف پذیری
شما میتوانید از رگرسیون لجستیک برای یافتن پاسخهایی به سوالاتی که نتایج محدودی دارند استفاده کنید. همچنین میتوان از آن برای پیشپردازش دادهها بهره برد. به عنوان مثال، میتوانید دادههایی با دامنههای وسیع (مانند تراکنش های بانکی) را با استفاده از رگرسیون لجستیک به دامنه های کوچک تر و محدودتری تبدیل کنید و سپس این مجموعه داده کوچکتر را با استفاده از سایر تکنیک های یادگیری ماشین برای تحلیل دقیقتر پردازش کنید. -
شفافیت
تحلیل رگرسیون لجستیک به توسعه دهندگان دید بهتری نسبت به فرآیندهای داخلی نرم افزار نسبت به سایر تکنیک های تحلیل داده میدهد. رفع خطا و عیب یابی در این مدلها نیز آسانتر است، زیرا محاسبات آنها از پیچیدگی کمتری برخوردار است.
کاربردهای رگرسیون لجستیک
رگرسیون لجستیک در بسیاری از صنایع مختلف، کاربردهای واقعی و متنوعی دارد:
-
صنایع تولیدی
شرکت های تولیدی از رگرسیون لجستیک برای تخمین احتمال خرابی قطعات در ماشین آلات استفاده می کنند. سپس بر اساس این تخمین، برنامه ریزی های نگهداری را انجام میدهند تا از خرابی های آتی جلوگیری کنند. این امر به کاهش هزینه های تعمیر و نگهداری و بهبود بهره وری تولید منجر می شود. -
حوزه بهداشت و درمان
پژوهشگران پزشکی از مدلهای رگرسیون لجستیک برای پیشبینی احتمال بروز بیماریها در بیماران استفاده میکنند. آنها میتوانند تأثیر عوامل مختلف مانند سابقه خانوادگی یا ژنها را بر روی بیماریها مقایسه کنند و برنامههای مراقبت و درمان پیشگیرانه را بر این اساس تنظیم نمایند. -
مالی و بانکی
شرکت های مالی از رگرسیون لجستیک برای تحلیل تراکنشهای مالی و شناسایی تراکنش های مشکوک به تقلب استفاده می کنند. همچنین، ارزیابی ریسک در بررسی درخواست های وام و بیمه با استفاده از این مدلها صورت می گیرد. این مدل ها بهویژه در شرایطی که نتایج تحلیل به صورت “پرخطر” یا “کمخطر” یا “تقلبی” و “غیرتقلبی” مشخص می شوند، بسیار مفید هستند. -
بازاریابی
ابزارهای تبلیغاتی آنلاین با استفاده از مدل رگرسیون لجستیک، پیش بینی میکنند که آیا کاربران روی یک تبلیغ کلیک خواهند کرد یا خیر. این تحلیل به بازاریابان کمک میکند تا واکنش های کاربران به کلمات و تصاویر مختلف را بررسی کنند و تبلیغاتی با عملکرد بالاتر ایجاد کنند که مخاطبان بیشتری را جذب کند. -
شناسایی تقلب
مدلهای رگرسیون لجستیک میتوانند به تیمها در شناسایی ناهنجاریهای دادهها کمک کنند که پیشبینیکننده تقلب هستند. رفتارها یا ویژگیهای خاصی ممکن است با فعالیتهای تقلبی ارتباط بیشتری داشته باشند که این موضوع بهویژه برای بانکها و مؤسسات مالی دیگر در محافظت از مشتریانشان مفید است. شرکتهای مبتنی بر SaaS نیز شروع به پذیرش این شیوهها کردهاند تا حسابهای کاربری تقلبی را از مجموعه دادههای خود حذف کنند، بهویژه زمانی که به تجزیه و تحلیل دادهها در مورد عملکرد کسبوکار میپردازند. -
پیشبینی بیماری
در زمینه پزشکی، این رویکرد تحلیلی میتواند برای پیشبینی احتمال بروز بیماری یا مشکلات سلامتی در یک جمعیت خاص استفاده شود. سازمانهای بهداشتی میتوانند برای افرادی که نشاندهنده تمایل بیشتری به بیماریهای خاص هستند، مراقبتهای پیشگیرانه برقرار کنند. -
پیشبینی ریزش مشتری
رفتارهای خاص ممکن است نشانهای از ریزش مشتری (churn) در بخشهای مختلف یک سازمان باشد. بهعنوان مثال، تیمهای منابع انسانی و مدیریت ممکن است بخواهند بدانند آیا کارکنان با عملکرد بالا در شرکت در معرض خطر ترک سازمان هستند یا خیر؛ این نوع بینش میتواند به گفتگوهایی منجر شود تا مشکلات موجود در شرکت، مانند فرهنگ یا حقوق و دستمزد، شناسایی شود. از طرف دیگر، سازمان فروش ممکن است بخواهد بداند کدام یک از مشتریان آنها در خطر انتقال کسبوکار خود به سمت رقبای دیگر هستند. این میتواند به تیمها کمک کند تا استراتژیهای نگهداری را برای جلوگیری از از دست دادن درآمد ایجاد کنند.
تحلیل رگرسیون چگونه کار میکند؟
تحلیل رگرسیون یکی از تکنیکهای متداول در یادگیری ماشین است که برای یافتن رابطه بین متغیرها و پیشبینی مقادیر آینده بر اساس دادههای موجود استفاده میشود. رگرسیون لجستیک یکی از انواع مختلف تحلیلهای رگرسیون است که معمولاً توسط دانشمندان داده در یادگیری ماشین (ML) مورد استفاده قرار میگیرد. برای درک بهتر رگرسیون لجستیک، ابتدا باید با مفهوم تحلیل رگرسیون آشنا شویم. در این بخش با استفاده از مثال رگرسیون خطی، نحوه کار تحلیل رگرسیون را توضیح میدهیم.
مراحل انجام تحلیل رگرسیون:
-
شناسایی سؤال اصلی: هر تحلیل دادهای با یک سؤال تجاری یا تحقیقاتی شروع میشود. برای رگرسیون لجستیک، بهتر است سؤالی مطرح کنید که نتایج خاصی را به دنبال داشته باشد، مانند:
- آیا روزهای بارانی بر فروش ماهانه ما تأثیر دارند؟ (پاسخ: بله یا خیر)
- چه نوع فعالیتی با کارت اعتباری توسط مشتری انجام میشود؟ (پاسخ: معتبر، تقلبی، یا احتمالاً تقلبی)
-
جمعآوری دادههای تاریخی: پس از شناسایی سؤال، باید عوامل دادهای مرتبط را تعیین و دادههای گذشته را برای همه این عوامل جمعآوری کنید. برای مثال، برای پاسخ به سؤال اول، میتوانید تعداد روزهای بارانی و میزان فروش ماهانه را برای هر ماه در سه سال گذشته جمعآوری کنید.
-
آموزش مدل تحلیل رگرسیون: سپس دادههای تاریخی را با استفاده از نرمافزارهای رگرسیون پردازش میکنید. نرمافزار، نقاط داده مختلف را با استفاده از معادلات ریاضی به هم متصل میکند. برای مثال، اگر تعداد روزهای بارانی در سه ماه به ترتیب ۳، ۵ و ۸ و تعداد فروش در همان ماهها ۸، ۱۲ و ۱۸ باشد، الگوریتم رگرسیون رابطه بین این دو متغیر را با معادله زیر برقرار میکند:
تعداد فروش = 2 × (تعداد روزهای بارانی) + 2 -
پیشبینی مقادیر ناشناخته: برای مقادیر ناشناخته، نرمافزار از این معادله برای پیشبینی استفاده میکند. مثلاً اگر بدانید که در ماه جولای شش روز بارانی خواهد بود، نرمافزار میزان فروش ماه جولای را ۱۴ پیشبینی میکند.
رگرسیون لجستیک چگونه کار میکند؟
معادلات و متغیرها
در ریاضیات، معادلات رابطه بین دو متغیر x و y را نشان میدهند. میتوان از این معادلات برای رسم نمودار بر روی محورهای x و y استفاده کرد. به عنوان مثال، اگر نمودار تابع y=2×x را رسم کنید، یک خط مستقیم به دست خواهید آورد؛ بنابراین، به این تابع، تابع خطی نیز میگویند.
در آمار، متغیرها عواملی از داده هستند که مقادیر آنها تغییر میکنند. برخی متغیرها مستقل یا متغیرهای توضیحی نامیده میشوند که علت یک نتیجه را تشکیل میدهند. سایر متغیرها وابسته یا متغیرهای پاسخ نامیده میشوند که مقادیر آنها به متغیرهای مستقل بستگی دارد.
رگرسیون لجستیک، با استفاده از دادههای تاریخی، بررسی میکند که چگونه متغیرهای مستقل بر متغیر وابسته تأثیر میگذارند.
تابع رگرسیون لجستیک
رگرسیون لجستیک یک مدل آماری است که از تابع لجستیک یا تابع “لاگیت” برای برقرار کردن رابطه بین x و y استفاده میکند. تابع لجستیک، y را به صورت تابع سیگموئید از x نگاشت میکند. اگر این معادله رگرسیون لجستیک را رسم کنید، یک منحنی S شکل (منحنی سیگموئید) به دست خواهید آورد.
F(x) = 1 / (1 + e^(-x))
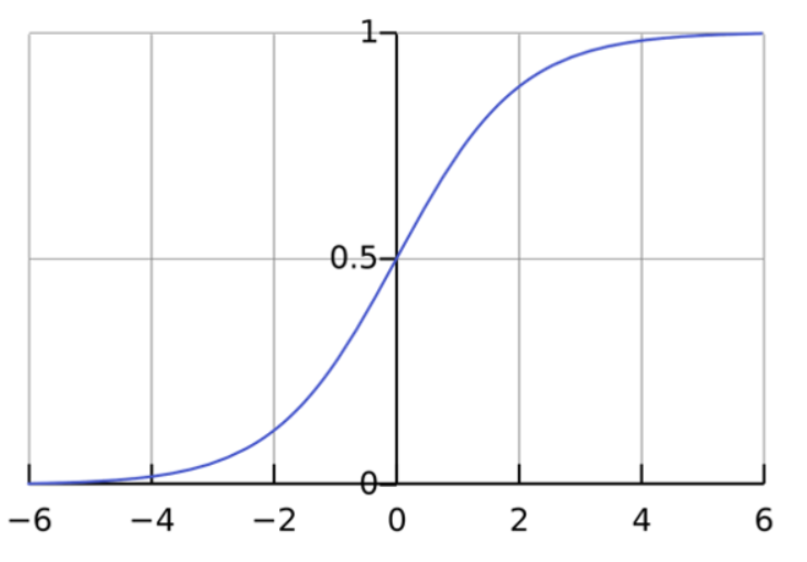
همانطور که مشاهده میکنید، تابع لاگیت مقادیر متغیر وابسته را بین ۰ و ۱ نگه میدارد، صرف نظر از مقادیر متغیر مستقل. این ویژگی به رگرسیون لجستیک امکان میدهد تا مقادیر متغیر وابسته را بهخوبی تخمین بزند.
تحلیل رگرسیون لجستیک با چند متغیر مستقل
در بسیاری از موارد، چندین متغیر توضیحی (مستقل) بر مقدار متغیر وابسته تأثیر میگذارند. برای مدلسازی چنین مجموعه دادههایی، فرمولهای رگرسیون لجستیک فرض میکنند که بین متغیرهای مستقل مختلف، یک رابطه خطی برقرار است. تابع سیگموئید را میتوان به صورت زیر اصلاح کرد تا خروجی نهایی متغیر وابسته را محاسبه کرد:
y = f(β0 + β1×1 + β2×2 + … + βnxn)
در این فرمول، نماد β ضریب رگرسیون را نشان میدهد. مدل لاگیت میتواند این مقادیر ضریب را هنگامی که یک مجموعه داده آزمایشی بزرگ با مقادیر شناخته شده از هر دو متغیر وابسته و مستقل ارائه شود، محاسبه کند.
شانس موفقیت (Log Odds)
مدل لاگیت همچنین میتواند نسبت موفقیت به شکست یا شانس (Odds) را تعیین کند. به عنوان مثال، اگر در بازی پوکر با دوستانتان در ۱۰ دست، ۴ دست را برنده شوید، شانس برد شما ۴ به ۶ است (چهار برنده به شش بازنده)، که همان نسبت موفقیت به شکست است. احتمال برد، از طرف دیگر، ۴ به ۱۰ خواهد بود.
ریاضیاتی، شانس شما به صورت زیر بیان میشود:
p / (1 – p)
و لاگاریتم شانس به صورت زیر محاسبه میشود:
log(p / (1 – p))
فرمول تابع رگرسیون لجستیک
فرمول تابع رگرسیون لجستیک به شرح زیر است:
توضیح اجزای فرمول:
y:
احتمال وقوع یک رویداد است. این مقدار بین ۰ و ۱ قرار دارد و نشاندهنده احتمال اینکه متغیر وابسته (مثل موفقیت یا شکست) در یک موقعیت خاص رخ دهد.
e:
عدد اویلر، که تقریباً برابر با ۲.۷۱۸۲۸ است. این عدد در ریاضیات و آمار به طور گستردهای استفاده میشود.
β₀:
عرض از مبدأ (intercept) است. این پارامتر به عنوان مقدار اولیه تابع لجستیک عمل میکند زمانی که همه متغیرهای مستقل برابر با صفر هستند.
β₁, β₂, …, βₙ:
ضرایب رگرسیون هستند که نشاندهنده تأثیر هر یک از متغیرهای مستقل بر احتمال وقوع رویداد است. این ضرایب مشخص میکنند که تغییر در هر یک از متغیرهای مستقل به چه میزان بر احتمال y تأثیر دارد.
x₁, x₂, …, xₙ:
مقادیر متغیرهای مستقل هستند. این متغیرها ورودیهایی هستند که بر نتیجه نهایی تأثیر میگذارند.
تفسیر رگرسیون لجستیک
تعبیر لاگ شانسها در تحلیل دادههای رگرسیون لجستیک میتواند دشوار باشد. به همین دلیل، تبدیل تخمینهای بتا به یک نسبت شانس (OR) معمول است که این کار تفسیر نتایج را تسهیل میکند. نسبت شانس نشاندهنده شانس وقوع یک نتیجه خاص است، با توجه به یک رویداد خاص، در مقایسه با شانس وقوع آن نتیجه در غیاب آن رویداد.
تفسیر نسبت شانس (OR):
-
نسبت شانس بزرگتر از ۱: اگر OR بزرگتر از ۱ باشد، این نشان میدهد که آن رویداد با احتمال بیشتری به وقوع نتیجه خاصی مرتبط است. به عبارت دیگر، وقوع آن رویداد شانس موفقیت را افزایش میدهد.
-
نسبت شانس کوچکتر از ۱: اگر OR کوچکتر از ۱ باشد، این نشان میدهد که آن رویداد با احتمال کمتری به وقوع نتیجه خاصی مرتبط است. به این معنا که وقوع آن رویداد شانس موفقیت را کاهش میدهد.
تفسیر نسبت شانس در معادله:
با توجه به معادلهای که ذکر شد، میتوان تفسیر نسبت شانس را به صورت زیر بیان کرد: شانس موفقیت به ازای هر افزایش c واحدی در x به اندازه exp(cB1) تغییر میکند.
مثال:
به عنوان مثال، فرض کنید میخواهیم شانس بقای یک فرد در کشتی تایتانیک را بر اساس جنسیت او تخمین بزنیم و نسبت شانس برای مردان برابر با ۰.۰۸۱۰ باشد. در اینجا، نسبت شانس را میتوان به این صورت تفسیر کرد:
- شانس بقا برای مردان در مقایسه با زنان، به مقدار ۰.۰۸۱۰ کاهش یافته است. به عبارت دیگر، مردان به طور قابل توجهی کمتر از زنان شانس بقا دارند، با ثابت نگه داشتن سایر متغیرها.
انواع تحلیل رگرسیون لجستیک
بسته به نوع متغیر وابسته، سه نوع رگرسیون لجستیک وجود دارد:
رگرسیون لجستیک باینری (Binary Logistic Regression)
رگرسیون لجستیک باینری برای مسائل دسته بندی باینری که تنها دو نتیجه ممکن دارند، بسیار مناسب است. متغیر وابسته تنها میتواند دو مقدار داشته باشد، مانند بله و خیر یا ۰ و ۱.
حتی اگر تابع لجستیک یک بازهای از مقادیر بین ۰ و ۱ را محاسبه کند، مدل رگرسیون باینری پاسخها را به نزدیکترین مقادیر گرد میکند. به طور معمول، پاسخهای کمتر از ۰.۵ به ۰ و پاسخهای بیشتر از ۰.۵ به ۱ گرد میشوند تا خروجی دودویی داشته باشد.
رگرسیون لجستیک چندحالته (Multinomial Logistic Regression)
رگرسیون چندحالته میتواند مسائل با چندین نتیجه ممکن را تحلیل کند، به شرط آن که تعداد نتایج محدود باشد. برای مثال، میتواند پیشبینی کند که قیمت خانهها بر اساس دادههای جمعیتی ۲۵٪، ۵۰٪، ۷۵٪ یا ۱۰۰٪ افزایش خواهد یافت، اما نمیتواند مقدار دقیق قیمت خانه را پیشبینی کند.
رگرسیون لجستیک ترتیبی (Ordinal Logistic Regression)
رگرسیون ترتیبی یا مدل لاجیت ترتیبی، نوع خاصی از رگرسیون چندحالته است که برای مسائلی که اعداد نمایانگر رتبهها بهجای مقادیر واقعی هستند، استفاده میشود. به عنوان مثال، میتوانید از رگرسیون ترتیبی برای پیشبینی پاسخ یک پرسشنامه استفاده کنید که از مشتریان میخواهد خدمات شما را به صورت ضعیف، متوسط، خوب یا عالی رتبهبندی کنند. این مدل براساس مقادیر عددی مانند تعداد خریدهای مشتریان از شما در طول سال کار میکند.
رگرسیون لجستیک و ماشین لرنینگ
رگرسیون لجستیک در حوزه یادگیری ماشین به خانواده مدلهای یادگیری تحت نظارت تعلق دارد. این مدل همچنین به عنوان یک مدل تمایزی شناخته میشود، به این معنی که سعی میکند بین کلاسها یا دستهها تمایز قائل شود. برعکس الگوریتمهای تولیدی، مانند نایو بیز، این مدل نمیتواند اطلاعاتی مانند یک تصویر از کلاسی که میخواهد پیشبینی کند (مثلاً یک تصویر از گربه) تولید کند.
در گذشته، اشاره کردیم که رگرسیون لجستیک برای تعیین ضرایب بتا (β) مدل، تابع لگاریتم احتمال را به حداکثر میرساند. این موضوع در زمینه یادگیری ماشین کمی متفاوت است. در اینجا، تابع منفی لگاریتم احتمال به عنوان تابع هزینه (loss function) استفاده میشود و با استفاده از روش نزول گرادیان (gradient descent) به دنبال یافتن حداکثر جهانی است. این یک روش دیگر برای رسیدن به همان تخمینهای قبلی است.
رگرسیون لجستیک ممکن است به اورفیت (overfitting) حساس باشد، بهویژه زمانی که تعداد زیادی متغیر پیشبین در مدل وجود داشته باشد. معمولاً از تکنیکهای منظمسازی (regularization) استفاده میشود تا ضرایب بزرگ را در صورتی که مدل با ابعاد بالا مواجه شود، جریمه کند.
مقایسه رگرسیون لجستیک با دیگر تکنیک های یادگیری ماشین
در یادگیری ماشین، دو تکنیک متداول برای تحلیل دادهها استفاده میشود: رگرسیون خطی و یادگیری عمیق. در ادامه به بررسی این تکنیکها و مقایسه آنها با رگرسیون لجستیک میپردازیم.
رگرسیون خطی
رگرسیون خطی، رابطه بین متغیرهای مستقل و وابسته را با استفاده از ترکیبی خطی مدلسازی میکند. معادله رگرسیون خطی به صورت زیر بیان میشود:
y = β0X0 + β1X1 + β2X2 + … + βnXn + ε
که در آن، β0 تا βn و ε ضرایب رگرسیون هستند.
مقایسه رگرسیون لجستیک و رگرسیون خطی
رگرسیون خطی برای پیش بینی متغیرهای وابسته پیوسته (Continuous Dependent Variables) بهکار میرود. متغیر پیوسته میتواند طیفی از مقادیر، مانند قیمت یا سن، داشته باشد. به عنوان مثال، رگرسیون خطی میتواند به سؤالاتی مانند «قیمت برنج در ۱۰ سال آینده چه مقدار خواهد بود؟» پاسخ دهد.
در مقابل، رگرسیون لجستیک یک الگوریتم دسته بندی (Classification) است و نمی تواند مقادیر واقعی برای دادههای پیوسته را پیش بینی کند. به جای آن، رگرسیون لجستیک به سؤالاتی مانند «آیا قیمت برنج در ۱۰ سال آینده ۵۰٪ افزایش خواهد یافت؟» پاسخ میدهد.
یادگیری عمیق
یادگیری عمیق از شبکههای عصبی یا مؤلفههای نرمافزاریای که مغز انسان را شبیهسازی میکنند، برای تحلیل اطلاعات استفاده میکند. محاسبات یادگیری عمیق بر اساس مفهوم ریاضیاتی بردارها (Vectors) انجام میشود.
مقایسه رگرسیون لجستیک و یادگیری عمیق
رگرسیون لجستیک از نظر محاسباتی پیچیدگی کمتری نسبت به یادگیری عمیق دارد و نیاز به منابع کمتری مانند پردازشگر و حافظه دارد. همچنین، محاسبات رگرسیون لجستیک قابل فهمتر و شفافتر است و توسعه دهندگان بهراحتی میتوانند آنها را بررسی و اصلاح کنند.
از طرف دیگر، یادگیری عمیق پیچیدگی بیشتری دارد و محاسبات آن اغلب به صورت خودکار و بدون دخالت مستقیم انسان انجام میشود. به دلیل همین پیچیدگی، توسعه دهندگان نمیتوانند بهراحتی محاسبات انجام شده را بررسی کنند یا تغییر دهند. بنابراین، یادگیری عمیق برای مسائل بسیار پیچیده که نیاز به پردازش حجم عظیمی از دادهها دارد، مناسبتر است.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]