
آنالیز رگرسیون

- 1- تحلیل رگرسیون
- 2- مقدمه ای بر تحلیل رگرسیون
- 3- آنالیز رگرسیون چندگانه
- 4- چه موقع از آنالیز رگرسیون چندگانه استفاده کنیم ؟
- 5- خروجی تحلیل رگرسیون چندگانه
- 6- برازش بیش از حد در رگرسیون
- 7- جلوگیری از تطبیق بیش از حد
- 8- نحوه تشخیص و جلوگیری از تطبیق بیش از حد
- 9- تحلیل رگرسیون در امور مالی
- 10- ابزارهای آنالیز رگرسیون
چکیده مقاله :
یکی دیگر از انالیز های معروف در تحلیل آماری ، آنالیز رگرسیون می باشد. تحلیل رگرسیون ارتباط بین متغییرهای وابسته و یک متغییر مستقل را مشخص می کند که اطلاعات بسیار مفید را می توان از آن استخراج کرد. در این مقاله به بررسی کامل آنالیز رگرسیون در حالت های خطی ساده و چندگانه خواهیم پرداخت. فرض های لازم برای این تحلیل را توضیح خواهیم داد و شما را با راه حل های مختلف درهنگام مواجه شدن با برازش بیش از حد ، ابزار لازم برای تحلیل و همچنین چند مثال خوب راهنمایی خواهیم کرد.
1- تحلیل رگرسیون
تعریف کلی : آنالیز رگرسیون یعنی تخمین روابط بین یک متغیر وابسته و یک یا چند متغیر مستقل
به بیان دقیق تر تحلیل رگرسیون مجموعه ای از روش های آماری است که برای تخمین روابط بین یک متغیر وابسته و یک یا چند متغیر مستقل استفاده می شود. می توان از آن برای ارزیابی قدرت رابطه بین متغیرها و مدل سازی رابطه آتی بین آنها استفاده کرد. برای مثال، ممکن است حدس بزنید که ارتباطی بین میزان غذا خوردن و وزن شما وجود دارد. تحلیل رگرسیون می تواند به شما در تعیین کمیت آن کمک کند.
قبل از شروع بهتر است مقاله زیر را مطالعه نمایید.
تحلیل رگرسیون معادله ای برای یک نمودار در اختیار شما قرار می دهد تا بتوانید در مورد داده های خود پیش بینی کنید. برای مثال، اگر در چند سال گذشته اضافه وزن داشتهاید، میتواند پیشبینی کند که اگر با همان سرعت به افزایش وزن خود ادامه دهید، در ده سال آینده چقدر وزن خواهید داشت. همچنین مجموعه ای از آمار (شامل مقدار p و ضریب همبستگی) را به شما می دهد تا به شما بگوید مدل شما چقدر دقیق است. اکثر دوره های آمار ابتدایی تکنیک های بسیار ابتدایی مانند ساختن نمودارهای پراکندگی و انجام رگرسیون خطی را پوشش می دهند. با این حال، ممکن است با تکنیک های پیشرفته تری مانند رگرسیون چندگانه مواجه شوید. در این مقاله به این موارد می پردازیم. آنالیز رگرسیون جزئی جدایی ناپذیر از تحلیل آماری است.
جهت آشنایی بیشتر می توانید مقاله زیر را با عنوان تحلیل آماری چیست مطالعه نمایید.

انواع آنالیز رگرسیون
تجزیه و تحلیل رگرسیون شامل چندین تغییر مانند خطی، خطی چندگانه و غیرخطی است. رایج ترین مدل ها خطی ساده و چندگانه خطی هستند. تحلیل رگرسیون غیرخطی معمولاً برای مجموعه دادههای پیچیدهتری استفاده میشود که در آن متغیرهای وابسته و مستقل یک رابطه غیرخطی را نشان میدهند.
2- مقدمه ای بر تحلیل رگرسیون
در آمار، خیره شدن به مجموعه ای از اعداد تصادفی در یک جدول و تلاش برای فهمیدن آن دشوار است. به عنوان مثال، گرم شدن زمین ممکن است میانگین بارش برف را در شهر شما کاهش دهد و از شما خواسته می شود پیش بینی کنید که فکر می کنید امسال چقدر برف خواهد بارید. با نگاهی به جدول زیر ممکن است حدود 10-20 اینچ را حدس بزنید. این حدس خوبی است، اما میتوانید با استفاده از رگرسیون حدس بهتری بزنید.
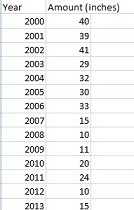
دیتای لازم برای تاثیر گرم شدن زمین بر میانگین بارش برف
اساسا، رگرسیون “بهترین حدس” در استفاده از مجموعه ای از داده ها برای انجام نوعی پیش بینی است. مجموعه ای از نقاط را به یک نمودار برازش می دهد. مجموعهای از ابزارها وجود دارد که میتوانند رگرسیون را برای شما اجرا کنند، از جمله Excel، که من در اینجا برای کمک به درک دادههای بارش برف از آن استفاده کردم:

خط رگرسیون عبوری از داده ها
فقط با نگاه کردن به خط رگرسیون که از داده ها عبور می کند، می توانید نتیجه بهتری بگیرید. می توانید ببینید که حدس اولیه (20 اینچ یا بیشتر) بسیار دور از ذهن بود. برای سال 2015، به نظر می رسد خط بین 5 تا 10 اینچ باشد! این ممکن است “به اندازه کافی خوب” باشد، اما رگرسیون همچنین یک معادله مفید به شما می دهد، که برای این نمودار این است:
y = -2.2923x + 4624.4.
معنی آن این است که می توانید مقدار x (سال) را وصل کنید و تخمین خوبی از بارش برف برای هر سال دریافت کنید. به عنوان مثال، 2005:
y = -2.2923(2005) + 4624.4 = 28.3385 اینچ، که بسیار نزدیک به رقم واقعی 30 اینچ برای آن سال است.
بهتر از همه، می توانید از معادله برای پیش بینی استفاده کنید. به عنوان مثال، چقدر برف در سال 2017 خواهد بارید؟
y = 2.2923 (2017) + 4624.4 = 0.8 اینچ.
رگرسیون همچنین به شما یک مقدار مربع R می دهد که برای این نمودار 0.702 است. این عدد به شما می گوید که مدل شما چقدر خوب است. مقادیر از 0 تا 1 متغیر است که 0 یک مدل وحشتناک و 1 یک مدل کامل است. همانطور که احتمالاً می بینید، 0.7 یک مدل نسبتاً مناسب است، بنابراین می توانید در پیش بینی آب و هوای خود نسبتاً مطمئن باشید!
1-2- مفروضات مدل خطی آنالیز رگرسیون
تحلیل رگرسیون خطی مبتنی بر شش فرض اساسی است:
1. متغیرهای وابسته و مستقل رابطه خطی بین شیب و برش را نشان می دهند.
2. متغیر مستقل تصادفی نیست.
3. مقدار باقیمانده (خطا) صفر است.
4. مقدار باقیمانده (خطا) در تمام مشاهدات ثابت است.
5. مقدار باقیمانده (خطا) در همه مشاهدات همبستگی ندارد.
6. مقادیر باقیمانده (خطا) از توزیع نرمال پیروی می کنند.
2-2- رگرسیون خطی ساده
رگرسیون خطی ساده مدلی است که رابطه بین یک متغیر وابسته و یک متغیر مستقل را ارزیابی می کند. مدل خطی ساده با استفاده از معادله زیر بیان می شود:
Y = a + bX + ε
که در آن:
• Y – متغیر وابسته
• X – متغیر مستقل (تبیینی).
• a – رهگیری
• b – شیب
• ϵ – باقیمانده (خطا)
3- آنالیز رگرسیون چندگانه
از تحلیل رگرسیون چندگانه برای بررسی اینکه آیا رابطه آماری معناداری بین مجموعهای از متغیرها وجود دارد یا خیر استفاده میشود. برای یافتن روندها در آن مجموعه داده ها استفاده می شود. آنالیز رگرسیون چندگانه تقریباً مشابه رگرسیون خطی ساده است. تنها تفاوت بین رگرسیون خطی ساده و رگرسیون چندگانه در تعداد پیش بینی کننده های (متغیرهای x) استفاده شده در رگرسیون است.
• تحلیل رگرسیون ساده از یک متغیر x برای هر متغیر وابسته «y» استفاده می کند. به عنوان مثال: (x1، Y).
• رگرسیون چندگانه از چندین متغیر “x” برای هر متغیر مستقل استفاده می کند: ((x1)،(x2)،(x3)،Y).
در رگرسیون خطی یک متغیره، یک متغیر وابسته (یعنی «فروش») را در مقابل یک متغیر مستقل (یعنی «سود») وارد میکنید. اما ممکن است برای شما جالب باشد که چگونه انواع مختلف فروش بر رگرسیون تأثیر می گذارد. می توانید X1 خود را به عنوان یک نوع فروش، X2 خود را به عنوان نوع دیگری از فروش و غیره تنظیم کنید.
به بیان دقیق تر همانطورکه گفته شد تحلیل رگرسیون خطی چندگانه اساساً مشابه مدل خطی ساده است، با این تفاوت که از متغیرهای مستقل متعدد در مدل استفاده شده است. نمایش ریاضی رگرسیون خطی چندگانه به صورت زیر است:
Y = a + bX1 + cX2 + dX3 + ε
که در آن:
• Y – متغیر وابسته
• X1، X2، X3 – متغیرهای مستقل (توضیح دهنده).
• a – رهگیری
• b، c، d – شیب ها
• ϵ – باقیمانده (خطا)
رگرسیون خطی چندگانه از شرایط مشابه مدل خطی ساده پیروی می کند. با این حال، از آنجایی که چندین متغیر مستقل در تحلیل خطی چندگانه وجود دارد، شرط الزامی دیگری برای مدل وجود دارد:
• غیر هم خطی بودن: متغیرهای مستقل باید حداقل همبستگی را با یکدیگر نشان دهند. اگر متغیرهای مستقل با یکدیگر همبستگی بالایی داشته باشند، ارزیابی روابط واقعی بین متغیرهای وابسته و مستقل دشوار خواهد بود.
4- چه موقع از آنالیز رگرسیون چندگانه استفاده کنیم ؟
رگرسیون خطی معمولی معمولاً برای در نظر گرفتن همه عوامل واقعی که بر یک نتیجه تأثیر دارند کافی نیست. به عنوان مثال، نمودار زیر یک متغیر منفرد (تعداد پزشکان) را در برابر متغیر دیگری (امید به زندگی زنان) ترسیم می کند.

رابطه بین امید به زندگی زنان و تعداد پزشکان
از این نمودار ممکن است به نظر برسد که بین امید به زندگی زنان و تعداد پزشکان در جمعیت رابطه وجود دارد. در واقع، این احتمالاً درست است و می توانید بگویید که یک راه حل ساده است: پزشکان بیشتری را در جمعیت قرار دهید تا امید به زندگی را افزایش دهید. اما واقعیت این است که شما باید به عوامل دیگری مانند احتمال اینکه پزشکان در مناطق روستایی تحصیلات یا تجربه کمتری داشته باشند، توجه کنید. یا شاید آنها به امکانات پزشکی مانند مراکز اصلی دسترسی ندارند. افزودن این عوامل اضافی باعث می شود که متغیرهای وابسته اضافی را به تحلیل رگرسیون خود اضافه کنید و یک مدل تحلیل رگرسیون چندگانه ایجاد کنید.
5- خروجی تحلیل رگرسیون چندگانه
تحلیل رگرسیون همیشه در نرم افزارهایی مانند Excel یا SPSS انجام می شود. خروجی با توجه به تعداد متغیرهایی که دارید متفاوت است، اما اساساً همان نوع خروجی است که در یک رگرسیون خطی ساده پیدا می کنید. فقط موارد بیشتری از آن وجود دارد:
• رگرسیون ساده: Y = b0 + b1 x.
• رگرسیون چندگانه: Y = b0 + b1 x1 + b0 + b1 x2…b0…b1 xn.
خروجی شامل یک خلاصه، شبیه به یک خلاصه برای رگرسیون خطی ساده است، که شامل موارد زیر است:
• R (ضریب همبستگی چندگانه)،
• مربع R (ضریب تعیین)،
• مربع R تنظیم شده،
• خطای استاندارد برآورد.
این آمار به شما کمک می کند تا بفهمید یک مدل رگرسیون چقدر با داده ها مطابقت دارد. جدول آنالیز واریانس (ANOVA) در خروجی، p-value و f-statistic را به شما می دهد.
6- برازش بیش از حد در رگرسیون

برازش یا تطبیق بیش از حد
تطبیق بیش از حد یا برازش بیش از حد میتواند منجر به مدل ضعیفی برای دادههای شما شود. تطبیق بیش از حد جایی است که مدل شما برای دادههای شما بسیار پیچیده است و زمانی اتفاق میافتد که حجم نمونه شما خیلی کوچک باشد. اگر به اندازه کافی متغیرهای پیش بینی کننده را در مدل رگرسیونی خود قرار دهید، تقریباً همیشه مدلی دریافت خواهید کرد که مهم به نظر می رسد.
با اینکه یک مدل با برازش بیش از حد ممکن است به خوبی با ویژگیهای خاص دادههای شما مطابقت داشته باشد اما با نمونههای آزمایشی اضافی یا جمعیت کلی مطابقت نخواهد داشت. مدل
مقادیر p، R-Squared و ضرایب رگرسیون همگی می توانند گمراه کننده باشند. اساسا، شما درحال استفاده کردن از مجموعه کوچکی از داده ها هستید.
7- جلوگیری از تطبیق بیش از حد
در مدلسازی خطی (از جمله رگرسیون چندگانه)، شما باید حداقل 10-15 مشاهده برای هر عبارتی که سعی در برآورد آن دارید داشته باشید. با تعداد کمتر از این شما در معرض خطر برازش بیش از حد مدل خود هستید.
“شرایط” شامل:
• اثرات متقابل،
• عبارات چند جمله ای (برای مدل سازی خطوط منحنی)،
• متغیرهای پیش بینی کننده.
در حالی که این قانون سرانگشتی به طور کلی پذیرفته شده است، گرین (1991) این را یک گام فراتر می برد و پیشنهاد می کند که حداقل حجم نمونه برای هر رگرسیون باید 50 باشد، با 8 مشاهده اضافی در هر ترم. به عنوان مثال، اگر یک متغیر تعاملی و سه متغیر پیشبینیکننده دارید، به حدود 45 تا 60 آیتم در نمونه خود نیاز دارید تا از تطبیق بیشازحد جلوگیری کنید، یا 50 + 3(8) = 74 مورد طبق گرین.
استثناها
استثناهایی برای قانون کلی «10-15» وجود دارد. آنها عبارتند از:
1. زمانی که در داده های شما multicollinearity وجود دارد، یا اگر effect size کوچک است. اگر اینطور است، باید موارد بیشتری را وارد کنید (اگرچه، متأسفانه، هیچ قانون کلی برای اضافه کردن چند عبارت وجود ندارد!).
2. اگر از مدلهای رگرسیون لجستیک یا بقا استفاده میکنید، ممکن است بتوانید از 10 مشاهدات در هر پیشبینیکننده خلاص شوید، البته تا زمانی که extreme event probabilities و small effect sizes یا predictor variables با محدودههای کوتاهشده نداشته باشید.
8- نحوه تشخیص و جلوگیری از تطبیق بیش از حد
ساده ترین راه برای جلوگیری از برازش بیش از حد، افزایش حجم نمونه با جمع آوری داده های بیشتر است. اگر نمیتوانید این کار را انجام دهید، گزینه دوم این است که تعداد پیشبینیکنندهها را در مدل خود کاهش دهید – یا با ترکیب یا حذف آنها. آنالیز فاکتور روشی است که میتوانید برای شناسایی پیشبینیکنندههای مرتبط که ممکن است کاندیدای ترکیب باشند، استفاده کنید.
1-8- Cross-Validation
از اعتبار سنجی متقاطع برای تشخیص برازش بیش از حد استفاده کنید: این داده های شما را پارتیشن بندی می کند، مدل شما را تعمیم می دهد و مدلی را انتخاب می کند که بهترین کار را دارد. یکی از شکلهای اعتبارسنجی متقاطع به صورت R-square پیشبینی میشود. اکثر نرم افزارهای آماری خوب این آمار را شامل می شود که به صورت زیر محاسبه می شود:
• حذف یک مشاهده در یک زمان از داده های شما،
• تخمین معادله رگرسیون برای هر تکرار،
• استفاده از معادله رگرسیون برای پیش بینی مشاهده حذف شده.
با این حال، اعتبارسنجی متقاطع یک روش جادویی برای مجموعه دادههای کوچک نیست، و گاهی اوقات حتی یک مدل واضح با حجم نمونه مناسب نیز شناسایی نمیشود.
2-8- Shrinkage & Resampling
تکنیکهای کوچککردن و نمونهگیری مجدد (مانند این ماژول R) میتواند به شما کمک کند تا بفهمید مدل شما چقدر میتواند با یک نمونه جدید مطابقت داشته باشد.
3-8- Automated Methods
Automated stepwise regression نباید به عنوان یک راه حل برای برازش بیش از حد با مجموعه داده های کوچک استفاده شود. به گفته بابیاک (2004)
“The problems with automated selection conducted in this very typical manner are so numerous that it would be hard to catalogue all of them [in a journal article].”
9- تحلیل رگرسیون در امور مالی
تحلیل رگرسیون با کاربردهای متعددی در امور مالی همراه است. به عنوان مثال، روش آماری برای مدل قیمت گذاری دارایی سرمایه (CAPM) اساسی است. اساساً معادله CAPM مدلی است که رابطه بین بازده مورد انتظار یک دارایی و حق بیمه ریسک بازار را تعیین می کند. این تحلیل همچنین برای پیشبینی بازده اوراق بهادار بر اساس عوامل مختلف یا پیشبینی عملکرد یک تجارت استفاده میشود.
1-9- BETA و CAPM
در امور مالی، تحلیل رگرسیون برای محاسبه بتا (نوسان بازده نسبت به کل بازار) برای یک سهام استفاده می شود. با استفاده از تابع Slope می توان آن را در اکسل انجام داد.

محاسبه بتا
2-9- پیش بینی درآمدها و هزینه ها
هنگام پیشبینی صورتهای مالی برای یک شرکت، ممکن است انجام یک تحلیل رگرسیون چندگانه برای تعیین اینکه چگونه تغییرات در برخی مفروضات یا محرکهای کسب و کار بر درآمد یا هزینهها در آینده تأثیر میگذارد مفید باشد. به عنوان مثال، ممکن است ارتباط بسیار بالایی بین تعداد فروشندگان استخدام شده توسط یک شرکت، تعداد فروشگاه هایی که آنها در حال فعالیت هستند و درآمدی که کسب و کار ایجاد می کند وجود داشته باشد.

استفاده از تابع پیش بینی در اکسل
مثال بالا نحوه استفاده از تابع Forecast در اکسل را برای محاسبه درآمد یک شرکت بر اساس تعداد تبلیغاتی که اجرا می کند نشان می دهد.
10- ابزارهای آنالیز رگرسیون
اکسل یک ابزار محبوب برای انجام تجزیه و تحلیل رگرسیون اساسی در امور مالی است، با این حال، ابزارهای آماری بسیار پیشرفته تری وجود دارد که می توان از آنها استفاده کرد. پایتون و R هر دو زبانهای کدنویسی قدرتمندی هستند که برای انواع مدلسازی مالی از جمله رگرسیون محبوب شدهاند. این تکنیک ها بخش اصلی علم داده و یادگیری ماشین را تشکیل می دهند که در آن مدل ها برای تشخیص این روابط در داده ها آموزش می بینند.
جهت آشنایی بیشتر با روش های تحلیل می توانید مقاله زیر را مطالعه نمایید.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]