
آزمون فریدمن: تعریف، فرضیات، زمان استفاده و مثال

چکیده مقاله:
آزمون فریدمن ابزاری آماری برای مقایسه نمونهها یا اندازهگیریهای مکرر است زمانی که مفروضات پارامتریک برآورده نمیشوند. در واقع آزمون فریدمن توسعهای از آزمون Wilcoxon signed-rank test و آنالوگ ناپارامتری از اندازهگیری های تکراری یک طرفه است. در بسیاری از مواقع لازم است که اندازهگیریهای مکرر یا نمونهها با هم مقایسه شوند، مانند بررسی عملکردهای بیولوژیکی یک فرد در طول زمان یا اندازهگیری مکرر غلظت یک ماده شیمیایی در یک کشت سلولی. در چنین شرایطی، ممکن است از آزمون تحلیل واریانس یکطرفه (ANOVA) استفاده شود، اما همه مجموعه دادهها الزامات پارامتری این آزمون را برآورده نمیکنند و نیاز به جایگزینی مناسب وجود دارد. در این مقاله، یکی از این جایگزینها، یعنی آزمون فریدمن، فرضیات آن، زمان استفاده از آن و همچنین مثال عملی از این آزمون را بررسی میکنیم.
آزمون فریدمن چیست؟
آزمون فریدمن یک آزمون آماری ناپارامتری است که برای تحلیل داده های اندازه گیری مکرر استفاده می شود. این آزمون زمانی کاربرد دارد که فرضیه های نرمال بودن و همگنی واریانس ها برقرار نباشند، بنابراین به عنوان جایگزینی مناسب و مقاوم برای آزمون تحلیل واریانس با اندازه های مکرر (ANOVA) عمل می کند.
آزمون فریدمن، که گاهی اوقات به آن تحلیل واریانس دو طرفه فریدمن با رتبهها نیز گفته میشود، یک آزمون آماری ناپارامتری است که برای بررسی این موضوع استفاده میشود که آیا گروههای دارای سه یا بیشتر اندازهگیری مکرر با یکدیگر تفاوت دارند یا خیر. این آزمون زمانی به کار میرود که دادههای متغیر مورد نظر ترتیبی یا پیوسته باشند. این آزمون ناپارامتری است زیرا هیچگونه فرضی در مورد توزیع دادهها (مانند توزیع نرمال) ندارد. در عمل، آزمون فریدمن اغلب زمانی استفاده میشود که متغیر پیوسته الزامات لازم برای تحلیل واریانس یک طرفه (ANOVA) را برآورده نکند یا هنگامی که متغیر مورد نظر ترتیبی باشد.
نمونه وابسته (اندازه گیری مکرر) چیست؟
در یک نمونه وابسته، مقادیر اندازه گیری شده به هم مرتبط هستند. برای مثال، اگر نمونه ای از افرادی که عمل جراحی زانو انجام داده اند انتخاب شود و این افراد قبل از جراحی و یک هفته و دو هفته بعد از جراحی مورد بررسی قرار گیرند، یک نمونه وابسته محسوب می شود. این به این دلیل است که همان افراد در چندین نقطه زمانی مصاحبه شده اند.
مقایسه آزمون فریدمن با آزمون ANOVA با اندازه گیری های مکرر
شاید بپرسید که تحلیل واریانس با اندازه گیری های مکرر دقیقا همین موضوع را بررسی نمی کند، زیرا این آزمون نیز تفاوت بین سه یا چند نمونه وابسته را مورد آزمون قرار می دهد؟
بله، درست است. آزمون فریدمن معادل ناپارامتری تحلیل واریانس با اندازه گیری های مکرر است. اما تفاوت بین این دو آزمون چیست؟
تحلیل واریانس تفاوت بین مقادیر اندازه گیری شده در نمونه های وابسته را بررسی می کند، در حالی که آزمون فریدمن از رتبه ها به جای مقادیر واقعی اندازه گیری شده استفاده می کند.
چگونه رتبه ها محاسبه می شوند؟
در آزمون فریدمن، زمانی که یک فرد در یک نقطه زمانی بالاترین مقدار را دارد، رتبه 1 به آن اختصاص می یابد. نقطه زمانی با دومین مقدار بالاتر رتبه 2 و نقطه زمانی با کمترین مقدار رتبه 3 را می گیرد. این روند برای همه افراد یا همه ردیف ها انجام می شود. سپس مجموع رتبه های نقاط زمانی مختلف محاسبه می شود.
به عنوان مثال، در اولین نقطه زمانی مجموع رتبه ها برابر با 7، در دومین نقطه زمانی برابر با 8 و در سومین نقطه زمانی برابر با 9 است. حالا می توانیم بررسی کنیم که مجموع رتبه های این نقاط زمانی چقدر با هم تفاوت دارند.
چرا از رتبه ها استفاده می شود؟
مزیت بزرگ استفاده از رتبه ها این است که اگر میانگین تفاوت ها را بررسی نکنیم و به جای آن از مجموع رتبه ها استفاده کنیم، داده ها نیازی به توزیع نرمال ندارند. به بیان ساده، اگر داده های شما نرمال باشند، از آزمون های پارامتری استفاده می شود. برای بیش از دو نمونه وابسته، این آزمون ANOVA با اندازه گیری های مکرر است.
اما اگر داده های شما نرمال نباشند، از آزمون های ناپارامتری استفاده می شود. برای بیش از دو نمونه وابسته، این آزمون فریدمن است.
فرضیه ها در آزمون فریدمن
این موضوع ما را به سوال تحقیقاتی می رساند که می توانید با آزمون فریدمن به آن پاسخ دهید: آیا تفاوت معناداری بین بیش از دو گروه وابسته وجود دارد؟
- فرضیه صفر: تفاوت معناداری بین گروه های وابسته وجود ندارد.
- فرضیه جایگزین: تفاوت معناداری بین گروه های وابسته وجود دارد.
همانطور که قبلاً اشاره شد، آزمون فریدمن از مقادیر واقعی استفاده نمی کند، بلکه از رتبه ها استفاده می کند.
فرمول آزمون فریدمن
برای محاسبه آماره آزمون فریدمن که به آن F فریدمن نیز گفته میشود، از فرمول زیر استفاده میشود:
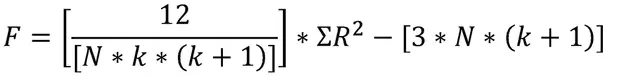
که در آن N تعداد افراد (نمونهها)، k تعداد شرایط (اندازهگیریها یا نمونهها) و R مجموع رتبهها برای هر یک از ستونهای دادهها است. جزئیات بیشتر در مثال عملی توضیح داده شده است.
مفروضات آزمون فریدمن
همانند تمامی آزمونهای آماری، آزمون فریدمن نیز دارای برخی فرضیات است که به شرح زیر هستند:
- دادهها باید ترتیبی یا پیوسته باشند. به عنوان مثال، یک متغیر ترتیبی میتواند یک سؤال نظرسنجی باشد که میزان رضایت را در یک مقیاس پنجدرجهای از «بسیار راضی» تا «بسیار ناراضی» ارزیابی میکند. مثالهایی از متغیرهای پیوسته شامل قد، دما و عملکرد در آزمون (از 0 تا 100) هستند.
- دادهها باید از یک گروه واحد باشند که در سه یا تعداد بیشتری از نقاط زمانی مختلف یا متغیرهای مرتبط اندازهگیری شده باشند. توجه داشته باشید که از نظر فنی، آزمون فریدمن را میتوان بر روی دو یا چند نمونه/اندازهگیری انجام داد، اما در این صورت این آزمون مشابه با آزمون علامت (Sign Test) میشود. بنابراین، آزمون فریدمن معمولاً برای سه یا تعداد بیشتری از نمونهها/اندازهگیریها به کار میرود.
- دادهها باید از یک نمونه تصادفی انتخاب شده از جامعهای باشند که محقق قصد دارد در مورد آن استنتاج انجام دهد.
- بلوکهای داده باید به صورت مستقل از هم باشند (مجموعههای داده نباید بر یکدیگر تأثیر بگذارند).
زمان استفاده از آزمون فریدمن
دو سناریوی مشخص وجود دارد که در آنها استفاده از آزمون فریدمن مفید است:
- زمانی که یک متغیر کمی (پیوسته یا ترتیبی) مشابه دو (و بیشتر اوقات سه) بار یا بیشتر از یک نمونه در نقاط زمانی مختلف اندازهگیری شده باشد (یا از نمونههای مختلفی که بر اساس متغیر دیگری با هم مطابقت داده شدهاند). به عنوان مثال، اندازه گیری های کلسترول از گروهی یکسان از بیماران در یک مطالعه در فواصل سهماهه.
- زمانی که دو (و بیشتر اوقات سه) یا چند متغیر کمی مرتبط از یک گروه در یک زمان مشابه اندازهگیری شده باشند. به عنوان مثال، پاسخ به سه سؤال مرتبط در یک نظرسنجی از همان گروه از افراد.
- این سناریوها در عمل متفاوت هستند، اما در واقع انواعی از یک سؤال آماری یکسان هستند که هر دو میتوانند تحت یک آزمون آماری واحد (آزمون فریدمن) بررسی شوند.
تفسیر آزمون فریدمن
مانند آزمون تحلیل واریانس یک طرفه (ANOVA)، نتایج آزمون فرضیه برای آزمون فریدمن به ما این ایده را میدهد که آیا مجموعههای مختلف از مقادیر به نحوی متفاوت هستند یا خیر، اما مشخص نمیکند که کدام یک متفاوت است. این موضوع معمولاً از طریق تحلیل میانه (به عنوان یک معیار گرایش مرکزی) و دامنه بین چارکی (IQR) (به عنوان یک معیار پراکندگی) مجموعه های مختلف و بررسی اینکه آیا الگویی از مقادیر بزرگتر یا کوچکتر در بین آنها وجود دارد، قابل انجام است.
مثال از آزمون فریدمن
شاید بخواهید بدانید که آیا درمان بعد از فتق دیسک روی درک درد بیمار تأثیر دارد یا خیر. برای این منظور، احساس درد را قبل از درمان، در میانه درمان و در انتهای درمان اندازه گیری می کنید. حالا می خواهید بدانید که آیا تفاوتی بین این نقاط زمانی مختلف وجود دارد یا خیر.
بنابراین، متغیر مستقل شما زمان یا پیشرفت درمان در طول زمان است. متغیر وابسته شما درک درد است. شما اکنون پیشرفتی از درک درد را برای هر فرد در طول زمان دارید و می خواهید بدانید که آیا درمان روی درک درد تأثیر داشته است یا خیر.
به بیان ساده، در یک حالت درمان تأثیر دارد و در حالت دیگر تأثیری روی درک درد ندارد. در طول زمان، درک درد در یک حالت تغییر نمی کند و در حالت دیگر تغییر می کند.
محاسبه آزمون فریدمن
فرض کنید می خواهید بدانید که آیا تفاوتی در پاسخگویی افراد در صبح، ظهر و شب وجود دارد یا خیر. برای این منظور، واکنش 7 نفر را در صبح، ظهر و شب اندازه گیری کرده اید.
در مرحله اول، باید به مقادیر، رتبه اختصاص دهید. برای این کار، هر ردیف را به طور جداگانه بررسی می کنیم.
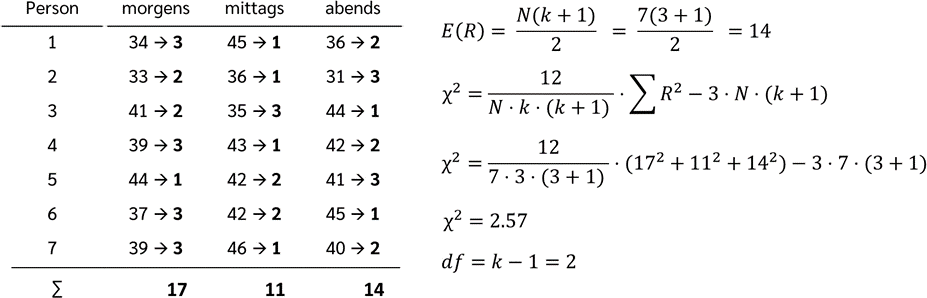
در ردیف اول یا فرد اول، 45 بزرگترین مقدار است و رتبه 1 می گیرد، سپس 36 با رتبه 2 و 34 با رتبه 3 قرار می گیرند. همین کار را برای ردیف دوم انجام می دهیم. در اینجا 36 بزرگترین مقدار است و رتبه 1 می گیرد، سپس 33 با رتبه 2 و 31 با رتبه 3 قرار می گیرند. این روند را برای هر ردیف ادامه می دهیم.
سپس می توانیم مجموع رتبه ها را برای هر زمان از روز محاسبه کنیم. به این ترتیب که همه رتبه ها در هر ستون جمع می شوند. در صبح، مجموع 17، در ظهر مجموع 11 و در شب مجموع 14 به دست می آید.
اگر بین نقاط زمانی مختلف از نظر زمان واکنش تفاوتی وجود نداشته باشد، انتظار می رود که در همه نقاط زمانی، مقدار مورد انتظار را داشته باشیم. مقدار مورد انتظار با استفاده از فرمول اول به دست می آید و در این مثال 14 است. بنابراین، اگر بین صبح، ظهر و شب تفاوتی وجود نداشته باشد، انتظار می رود مجموع رتبه ها در هر سه نقطه زمانی 14 باشد.
محاسبه مقدار Chi2
حال می توانیم مقدار Chi2 را محاسبه کنیم. این مقدار با استفاده از فرمول دوم به دست می آید. N تعداد افراد است، یعنی 7، k تعداد نقاط زمانی است، یعنی 3 و مجموع R2 برابر با 172+112+14217^2 + 11^2 + 14^2172+112+142 است. بنابراین، مقدار Chi2 برابر با 2.57 می شود.
حال باید تعداد درجه آزادی را پیدا کنیم. این مقدار برابر با تعداد نقاط زمانی منهای 1 است، بنابراین در مثال ما برابر با 2 می شود.
بررسی مقدار بحرانی Chi2 و سطح معناداری
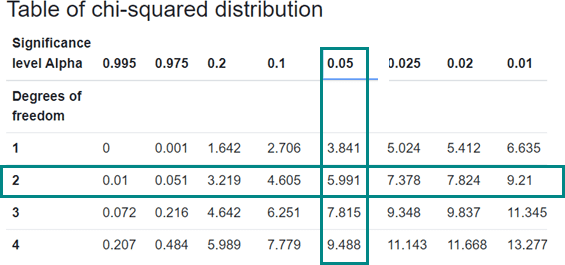
در این مرحله می توانیم مقدار بحرانی Chi2 را در جدول مقادیر بحرانی بخوانیم. برای این کار، از سطح معناداری از پیش تعیین شده، مثلاً 0.05، و تعداد درجه آزادی استفاده می کنیم. در اینجا مقدار بحرانی Chi2 برابر با 5.99 است. این مقدار بزرگتر از مقدار محاسبه شده ماست. بنابراین، فرضیه صفر رد نمی شود و بر اساس این داده ها، تفاوتی بین پاسخگویی در زمان های مختلف وجود ندارد. اگر مقدار محاسبه شده Chi2 بزرگتر از مقدار بحرانی بود، فرضیه صفر را رد می کردیم.
محاسبه آزمون فریدمن با استفاده از DATAtab
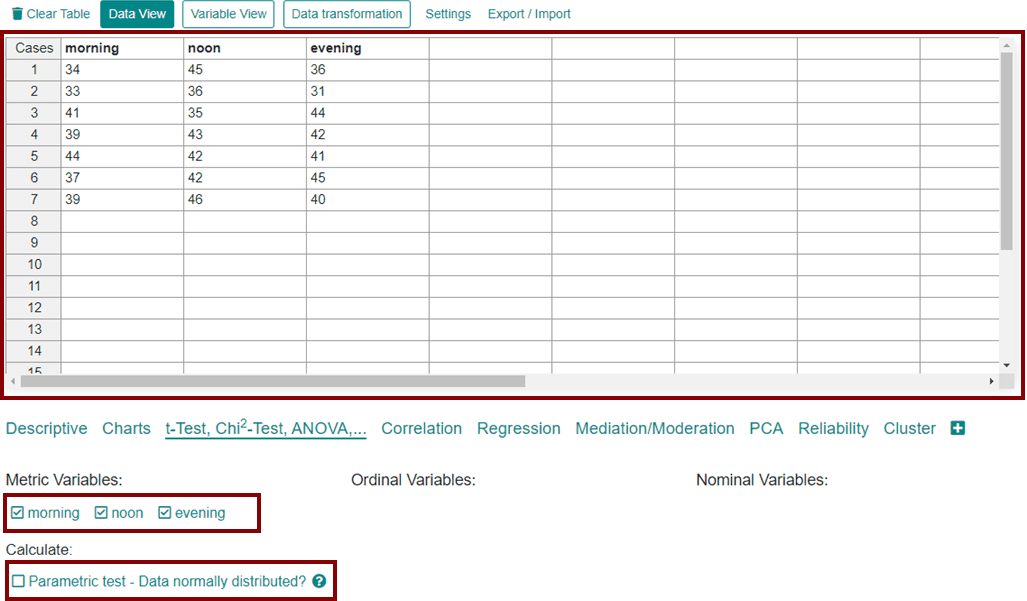
برای محاسبه آزمون فریدمن می توانید به سادگی از DATAtab استفاده کنید. برای این کار، کافی است به ماشین حساب آزمون فریدمن در DATAtab بروید و داده های خود را در جدول کپی کنید.
تفسیر نتایج آزمون فریدمن
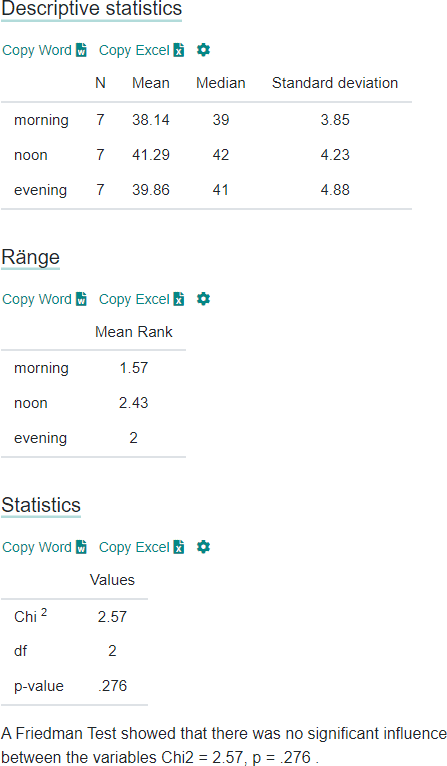
ابتدا آمار توصیفی را مشاهده می کنید. سپس می توانید مقدار p را بخوانید. اگر دقیقاً نمی دانید که چگونه مقدار p را تفسیر کنید، می توانید به سادگی به تفسیر کلمات نگاه کنید.
آزمون فریدمن نشان داد که تفاوت معناداری بین متغیرها وجود ندارد. Chi2 = 2.57، p = 0.276
اگر مقدار p شما بزرگتر از سطح معناداری تعیین شده شما باشد، در این صورت فرضیه صفر رد نمی شود. فرضیه صفر این است که بین گروه ها تفاوتی وجود ندارد. معمولاً سطح معناداری 0.05 در نظر گرفته می شود، بنابراین این مقدار p بزرگتر است.
آزمون Post-Hoc
علاوه بر این، DATAtab آزمون post-hoc را نیز فراهم می کند. اگر مقدار p شما کوچکتر از 0.05 باشد، می توانید در اینجا بررسی کنید که کدام گروه ها واقعاً با یکدیگر تفاوت دارند.
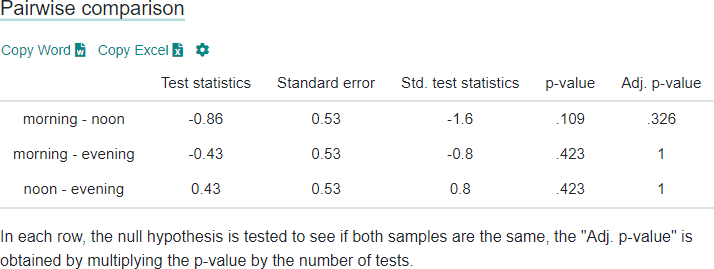
در اینجا، هر ردیف به دو گروه در نظر گرفته می شود و فرضیه صفر آزمون می شود که آیا هر دو نمونه یکسان هستند یا خیر. مقدار “Adjusted p-value” با ضرب مقدار p در تعداد آزمون ها به دست می آید.
اگر آزمون post-hoc نشان دهد که مقدار p کمتر از 0.05 است، فرض می شود که این گروه ها با هم متفاوت هستند.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]