
الگوریتم ژنتیک در پایتون: اجزا، مراحل پیاده سازی و مثال

چکیده مقاله:
الگوریتم ژنتیک در پایتون، تکنیک هایی مبتنی بر انتخاب طبیعی هستند که برای حل مسائل پیچیده مورد استفاده قرار می گیرند. این الگوریتم ها برای رسیدن به راه حل های منطقی برای مسائل، به جای روش های دیگر به کار می روند زیرا مسائل مورد نظر پیچیدگی زیادی دارند. در ادامه، اصول اولیه الگوریتم ژنتیک در پایتون و نحوه پیاده سازی آن، معرفی PyGad، بررسی یک مثال و کاربرد های آن مورد بررسی قرار می گیرند.
الگوریتم ژنتیک در پایتون چیست؟
تصور کنید که می خواهید مسیرهای حمل و نقل برای کامیون ها را بهینه کنید. هر کامیون مسیرهای احتمالی بسیاری برای تردد دارد و شما نیز با تعداد زیادی کامیون و توقف های متعددی روبرو هستید. تعداد بسیار زیاد این احتمال ها می تواند گیج کننده باشد و پیدا کردن بهترین راه حل، شبیه به جستجوی سوزنی در انبار کاه است.
برای حل مسائلی از این دست، می توان از مفهومی در زیست شناسی به نام تکامل الهام گرفت. در زیست شناسی، انتخاب طبیعی نیرویی است که تکامل را هدایت می کند. مسئله طبیعت این است که ترکیب های بهینه ای از صفات را پیدا کند که به یک موجود زنده اجازه بقا و تولید مثل بدهد. طبیعت از انتخاب طبیعی استفاده می کند تا مجموعه های مختلفی از صفات را در رقابت با یکدیگر قرار دهد و بهترین ترکیب ها را انتخاب کند.
به طور مشابه، می توانیم از این مفهوم برای ایجاد الگوریتمی استفاده کنیم که راه حل های مختلف را در برابر یکدیگر قرار داده و از فرآیند انتخاب برای “تکامل” آن ها به سمت بهترین راه حل استفاده کند. الگوریتم هایی که این کار را انجام می دهند، الگوریتم های ژنتیکی (GA) نامیده می شوند.
الگوریتم های ژنتیکی (GA) الگوریتم های جستجوی ابتکاری تطبیقی هستند که به دسته بزرگ تری از الگوریتم های تکاملی تعلق دارند. این الگوریتم ها بر اساس ایده های انتخاب طبیعی و ژنتیک عمل می کنند. آن ها با استفاده هوشمندانه از جستجوهای تصادفی و داده های تاریخی، جستجو را به سمت نواحی با عملکرد بهتر در فضای حل مسئله هدایت می کنند. این الگوریتم ها به طور معمول برای تولید راه حل های باکیفیت در مسائل بهینه سازی و جستجو مورد استفاده قرار می گیرند.
این مدل سازی ها فرآیند انتخاب طبیعی را شبیه سازی می کنند، به این معنا که گونه هایی که می توانند خود را با تغییرات محیطی سازگار کنند، زنده می مانند، تولید مثل می کنند و به نسل بعدی منتقل می شوند. به زبان ساده، آن ها مفهوم “بقای اصلح” را در میان افراد نسل های متوالی برای حل یک مسئله شبیه سازی می کنند. هر نسل شامل جمعیتی از افراد است که هر فرد، نمایانگر یک نقطه در فضای جستجو و یک راه حل ممکن می باشد. هر فرد به صورت یک رشته از کاراکتر، عدد صحیح، عدد اعشاری یا بیت ها نمایش داده می شود. این رشته مشابه کروموزوم است.
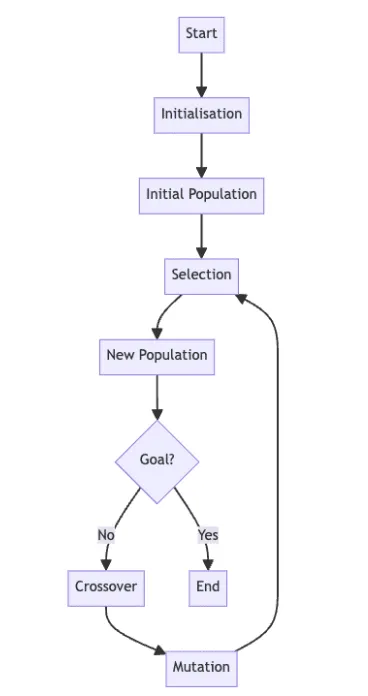
اجزای ژنتیکی
1. تابع برازندگی (Fitness Function)
تابع برازندگی میزان نزدیکی یک راه حل پیشنهادی به بهترین راه حل ممکن برای مسئله را ارزیابی می کند. این تابع یک سطح برازندگی برای هر فرد در جمعیت تعیین می کند که کیفیت یا کارایی نسل فعلی را توصیف می نماید. این امتیاز، معیار انتخاب است، به طوری که مقدار بالاتر برازندگی نشان دهنده راه حلی بهبود یافته می باشد.
به عنوان مثال، فرض کنید در حال کار با یک تابع واقعی f(x)f(x) هستیم که در آن xx مجموعه ای از پارامترها است. مقدار بهینه ای که باید پیدا کنیم xx است، به گونه ای که f(x)f(x) بزرگترین مقدار ممکن را داشته باشد.
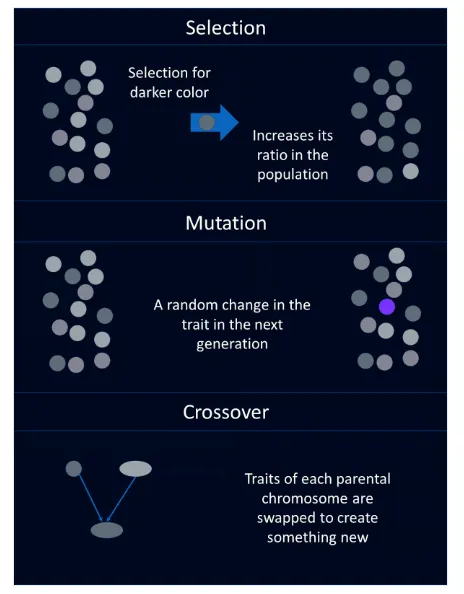
2. انتخاب (Selection)
این فرآیند تعیین می کند که کدام افراد در نسل حاضر باید انتخاب شوند تا تکثیر کنند و به نسل بعدی کمک کنند. روش های متعددی برای انتخاب وجود دارد که هر یک دارای ویژگی ها و زمینه های مناسب خاص خود هستند.
روش های انتخاب
- انتخاب به روش چرخ رولت (Roulette Wheel Selection):
بر اساس سطح برازندگی هر فرد، احتمال انتخاب آن فرد نیز حداکثر می شود. افراد با برازندگی بالاتر شانس بیشتری برای انتخاب دارند. - انتخاب به روش مسابقه ای (Tournament Selection):
یک گروه به صورت تصادفی انتخاب می شود و بهترین فرد از میان آن گروه برگزیده می شود. - انتخاب بر اساس رتبه (Rank-Based Selection):
افراد بر اساس سطح برازندگی مرتب می شوند و شانس انتخاب به طور متناسب با امتیازهای برازندگی تخصیص داده می شود.
3. ترکیب (Crossover)
ترکیب یکی از مفاهیم اساسی در الگوریتم های ژنتیکی است که هدف آن تبادل اطلاعات ژنتیکی بین دو والد برای تشکیل یک یا چند فرزند است. این فرآیند شباهت زیادی به ترکیب و بازآرایی ژنتیکی در زیست شناسی طبیعی دارد. با استفاده از اصول اولیه وراثت، ترکیب تلاش می کند تا فرزندانی تولید کند که ویژگی های مطلوب والدین را در خود داشته باشند و در نتیجه سازگاری بهتری در نسل های آینده داشته باشند. ترکیب، مفهومی گسترده است که به چندین نوع تقسیم می شود و هر نوع ویژگی ها و کاربرد های خاص خود را دارد.
مطلب پیشنهادی: الگوریتم کرم شب تاب چیست؟
انواع ترکیب
- ترکیب تک نقطه ای (Single-Point Crossover):
یک نقطه ترکیب در کروموزوم والدین انتخاب می شود و تنها یک ترکیب اتفاق می افتد. تا این نقطه تمام ژن ها از والد اول گرفته می شوند و از این نقطه به بعد تمام ژن ها از والد دوم گرفته می شوند. - ترکیب دو نقطه ای (Two-Point Crossover):
دو نقطه شکست انتخاب می شوند و بخشی از کروموزوم بین این دو نقطه بین والدین جا به جا می شود. این روش نسبت به ترکیب تک نقطه ای تبادل اطلاعات ژنتیکی بیشتری را ممکن می سازد.
مطلب پیشنهادی: مسئله کوله پشتی چیست؟
4. جهش (Mutation)
در الگوریتم های ژنتیکی، جهش، اهمیت بسیار زیادی دارد زیرا تنوع را فراهم می کند که عامل مهمی برای جلوگیری از همگرایی مستقیم به سمت ناحیه راه حل های بهینه می باشد. با ایجاد تغییرات تصادفی در رشته یک فرد، جهش به الگوریتم اجازه می دهد به نواحی دیگری از فضای حل دست یابد که تنها با عملیات ترکیب امکان پذیر نیست. این فرآیند تصادفی تضمین می کند که جمعیت در هر صورت تکامل یابد یا موقعیت خود را در نواحی فضای جستجو که به عنوان بهینه توسط الگوریتم ژنتیکی شناسایی شده اند، تغییر دهد.
PyGad چیست؟
PyGAD یک کتابخانه متن باز در پایتون است که برای پیاده سازی الگوریتم های ژنتیکی (Genetic Algorithms) و استفاده از آن ها در حل مسائل بهینه سازی و آموزش مدل های یادگیری ماشین طراحی شده است. این کتابخانه ابزارهای متنوعی برای ایجاد، تنظیم و اجرای الگوریتم های ژنتیکی فراهم می کند و به کاربران این امکان را می دهد که الگوریتم های خود را برای کاربرد های مختلف شخصی سازی کنند.
در مجموع، PyGAD یک ابزار بسیار کاربردی برای حل مسائل بهینه سازی به کمک الگوریتم های ژنتیک است که میتواند در طیف وسیعی از پروژه ها مورد استفاده قرار گیرد.
مراحل شبیه سازی الگوریتم ژنتیک در پایتون
الگوریتم ژنتیک در پایتون از سلسله مراحلی عبور می کند که شبیه سازی فرآیندهای تکامل طبیعی است این امر به منظور پیدا کردن حل های بهینه می باشد. این مراحل به جمعیت اجازه می دهد که در طول نسل ها تکامل یابد و کیفیت راه حل ها بهبود پیدا کند. در اینجا یک دستورالعمل کلی برای نحوه پیشرفت الگوریتم ژنتیکی آورده شده است:
مرحله 1: آغاز (Initialization)
مرحله آغازین در شبیه سازی الگوریتم ژنتیک با ایجاد یک جمعیت اولیه از افراد شروع می شود. هر فرد نماینده یک راه حل بالقوه برای مسئله مورد نظر است و معمولا به شکل یک کروموزوم نمایش داده می شود. کروموزوم ها می توانند به صورت رشته های باینری، آرایه های عددی، یا هر ساختار دیگری باشند که به مسئله خاص بستگی دارد. در این مرحله، تعداد مشخصی از افراد به صورت تصادفی تولید می شوند تا تنوع کافی در جمعیت اولیه وجود داشته باشد. این تنوع اولیه مهم است، زیرا می تواند الگوریتم را از گیر افتادن در بهینه های محلی باز دارد و به جستجوی گسترده در فضای راه حل کمک کند.
برای اجرای این مرحله در پایتون، می توان از کتابخانه هایی مانند NumPy برای تولید تصادفی جمعیت استفاده کرد. به عنوان مثال، اگر کروموزوم ها به صورت آرایه های عددی باشند، می توان با استفاده از توابع تصادفی، مقادیر اولیه را تولید کرد. همچنین، این مرحله می تواند شامل اعمال برخی محدودیت ها یا پیش شرط هایی باشد که برای مسئله خاص لازم است، مانند محدودیت های دامنه یا شرایط اولیه خاص.
مرحله 2: ارزیابی (Evaluation)
در این مرحله، کیفیت هر فرد در جمعیت با استفاده از یک تابع برازندگی محاسبه می شود. تابع برازندگی معیاری است که نشان می دهد یک راه حل چقدر خوب می تواند مسئله را حل کند یا به هدف مورد نظر نزدیک شود. تابع برازندگی باید به گونه ای طراحی شود که راه حل های بهتر دارای مقادیر برازندگی بالاتر باشند. این مرحله بسیار مهم است، زیرا عملکرد کل الگوریتم ژنتیک به دقت و کارایی این تابع بستگی دارد.
در پایتون، تابع برازندگی می تواند به صورت یک تابع یا متد تعریف شود که کروموزوم را به عنوان ورودی دریافت کرده و مقدار برازندگی آن را بر می گرداند. این تابع ممکن است شامل محاسبات پیچیده ای باشد که به طبیعت مسئله بستگی دارد. برای مثال، در مسئله کمینه سازی یا بیشینه سازی، این تابع می تواند شامل محاسبات ریاضی، تحلیل داده یا هر نوع عملیاتی باشد که کیفیت راه حل را ارزیابی می کند.
مرحله 3: انتخاب (Selection)
در مرحله انتخاب، افراد بر اساس برازندگی آن ها برای تولید مثل انتخاب می شوند. این مرحله تضمین می کند که افراد بهتر شانس بیشتری برای انتقال ژن های خود به نسل بعدی دارند. روش های مختلفی برای انتخاب وجود دارد، از جمله انتخاب به روش چرخ رولت، انتخاب به روش تورنمنت، و انتخاب به روش رتبه بندی. انتخاب مناسب ترین روش به طبیعت مسئله و نیازهای الگوریتم بستگی دارد.
در پایتون، روش های انتخاب می توانند با استفاده از توابع ساده یا الگوریتم های پیشرفته پیاده سازی شوند. به عنوان مثال، در روش چرخ رولت، احتمال انتخاب هر فرد متناسب با مقدار برازندگی آن است. این روش می تواند با استفاده از محاسبات احتمال و تولید اعداد تصادفی در پایتون انجام شود. همچنین، در روش تورنمنت، افراد به صورت گروهی مقایسه شده و بهترین فرد از هر گروه انتخاب می شود.
مرحله 4: ترکیب (Crossover)
مرحله ترکیب شامل ادغام مواد ژنتیکی والدین منتخب برای تولید فرزند های جدید است. هدف از این مرحله تولید تنوع در جمعیت و ایجاد راه حل های بالقوه جدید است. روش های مختلفی برای ترکیب وجود دارد، مانند ترکیب تک نقطه ای، ترکیب چند نقطه ای، و ترکیب یکنواخت. انتخاب روش مناسب به نوع داده های کروموزوم و ویژگی های مسئله بستگی دارد.
در پایتون، ترکیب می تواند با استفاده از برش آرایه ها یا استفاده از توابع کتابخانه ای انجام شود. به عنوان مثال، در ترکیب تک نقطه ای، یک نقطه تصادفی در طول کروموزوم انتخاب شده و قسمت های قبل و بعد از آن بین والدین تعویض می شوند. پیاده سازی این روش ها با استفاده از توابع تصادفی و عملیات روی داده ها قابل انجام است.
مرحله 5: جهش (Mutation)
جهش به منظور حفظ تنوع ژنتیکی در جمعیت انجام می شود. این مرحله شامل تغییرات تصادفی کوچک در کروموزوم های فرزند است. هدف از جهش جلوگیری از همگرایی زودرس الگوریتم و امکان جستجوی گسترده تر در فضای راه حل است. میزان جهش باید با دقت تنظیم شود، زیرا جهش بیش از حد می تواند باعث اختلال در روند الگوریتم شود و جهش کم ممکن است به کاهش تنوع جمعیت منجر شود.
در پایتون، جهش می تواند با تغییر تصادفی مقادیر یک یا چند ژن در کروموزوم انجام شود. به عنوان مثال، در کروموزوم های باینری، می توان با احتمال مشخصی بیت ها را از صفر به یک یا برعکس تغییر داد. این کار با استفاده از تولید اعداد تصادفی و تغییر مقادیر آرایه ها قابل انجام است.
مرحله 6: جایگزینی (Replacement)
در این مرحله، جمعیت قدیمی با استفاده از فرزند های جدید به روز رسانی می شود. روش های مختلفی برای جایگزینی وجود دارد. در برخی موارد، همه افراد قدیمی با فرزند های جدید جایگزین می شوند. در موارد دیگر، تنها بخشی از جمعیت قدیمی حفظ می شود و بخشی از آن با فرزند ها جایگزین می شود. هدف این مرحله حفظ تعادل بین تنوع و برازندگی جمعیت است.
در پایتون، می توان جایگزینی را با مرتب سازی افراد بر اساس برازندگی و انتخاب افراد بهتر انجام داد. همچنین، می توان ترکیبی از افراد قدیمی و جدید را برای نسل بعدی انتخاب کرد. روش های مختلف جایگزینی به نیازهای مسئله و الگوریتم بستگی دارد.
مرحله 7: تکرار (Repeat)
در نهایت، مراحل قبل تا زمانی که شرایط خاتمه برآورده شود، تکرار می شوند. شرایط خاتمه می تواند شامل تعداد مشخصی از نسل ها، رسیدن به مقدار مشخصی از برازندگی، یا توقف تغییرات در جمعیت باشد. این مرحله به الگوریتم اجازه می دهد که به تدریج تکامل یابد و راه حل های بهتری تولید کند.
در پایتون، این مرحله معمولا با استفاده از یک حلقه تکرار پیاده سازی می شود. داخل این حلقه، مراحل ارزیابی، انتخاب، ترکیب، جهش، و جایگزینی به ترتیب انجام می شوند. پایان حلقه با بررسی شرایط خاتمه تعیین می شود. تنظیم دقیق این شرایط می تواند تأثیر زیادی بر کارایی الگوریتم داشته باشد.
مثال شبیه سازی الگوریتم ژنتیک در پایتون
حال که درک خوبی از الگوریتم های ژنتیکی به وجود آمد و به طور کلی می دانیم که چگونه کار می کنند، بیایید الگوریتم ژنتیکی خود را بسازیم تا یک مسئله ساده بهینه سازی را حل کنیم.
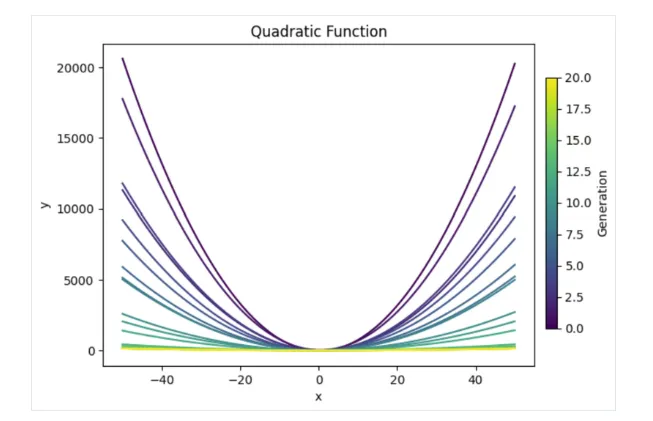
معادله y=ax^2 + bx + c وقتی رسم شود، یک پارابولا ایجاد می کند. ما از الگوریتم ژنتیکی استفاده خواهیم کرد تا ترکیب مقادیری برای a، b و c پیدا کنیم که باعث ایجاد کمترین انحنای پارابولا شود. در اینجا پیش نمایشی از آنچه که قرار است به دست آوریم آورده شده است:
1. وارد کردن کتابخانه ها
در بالای تابع خود، کتابخانه های لازم را وارد خواهیم کرد. از کتابخانه ‘random’ برای تولید مقادیر تصادفی برای جمعیت شروع استفاده خواهیم کرد. Numpy به طور کلی برای انجام هر نوع محاسبات ریاضی مفید است.
برای اطمینان از انجام درست کار نمودار رسم می کنیم به همین خاطر ‘matplotlib.pyplot’ را برای رسم گراف ها وارد خواهیم کرد.
علاوه بر این، برای چاپ نتایج مهم هر نسل (با فرض تعداد نسبتا کم نسل ها) به منظور واقف بودن بر تمام امور در طول شبیه سازی، ‘PrettyTable’ را وارد خواهیم کرد.
2. تعریف تابع برازندگی
در مرحله بعد باید تابع برازندگی را تعریف کنیم که برازندگی هر راه حل را ارزیابی کند. در این مورد، ما می خواهیم کم انحناترین منحنی u شکل را پیدا کنیم. بنابراین، مقدار 𝑦 را در راس منحنی و در نقاط x=−1 و x=1 محاسبه کرده سپس انحنا یا “curviness” گراف را به منظور تفاوت در مقدار در y این سه نقطه محاسبه می کنیم. از آنجا که ما می خواهیم کمترین انحنا را داشته باشیم، انحنا را منفی کرده تا تابع برازندگی را تکمیل کنیم.
3. ایجاد جمعیت اولیه
ما از کتابخانه ‘random’ برای تولید یک جمعیت از راه حل های تصادفی استفاده خواهیم کرد. هر فرد در این جمعیت مجموعه ای از مقادیر برای a، b، و c خواهد بود.
4. ایجاد تابع انتخاب
تابع انتخاب تعیین می کند که کدام افراد برای تولید مثل و ایجاد جمعیت بعدی انتخاب شوند. در این مثال، از فرآیند انتخاب مسابقه ای (Tournament Selection) استفاده خواهیم کرد، جایی که یک زیرمجموعه تصادفی از افراد در جمعیت انتخاب می شود و افراد با بالاترین برازندگی در آن زیرمجموعه برای تولید مثل انتخاب می شوند.
5. ایجاد تابع ترکیب (Crossover)
در مرحله بعد، یک تابع ساده برای استفاده از ترکیب خواهیم نوشت تا بر اساس راه حل های موجود، راه حل های جدید ایجاد کنیم. این تابع از اطلاعات ژنتیکی والدین استفاده می کند تا فرزندانی تولید کند که ویژگی های هر دو والد را به ارث ببرند.
6. طراحی تابع جهش (Mutation)
ما همچنین به یک تابع جهش نیاز داریم تا به نسل های بعدی تصادفی بودن اضافه کنیم. این کار از اهمیت بالایی برخوردار است زیرا تضمین می کند که تنوع کافی در هر نسل وجود دارد تا بتوان گزینه های مختلفی برای انتخاب داشت. جهش با ایجاد تغییرات کوچک در مقادیر موجود، امکان کشف نواحی جدید در فضای جستجو را فراهم می کند.
7. حلقه اصلی (Main Loop)
در این مرحله، باید حلقه اصلی را ایجاد کنیم که تمامی این بخش ها را کنار هم قرار داده و الگوریتم ما را اجرا کند. این حلقه مراحل زیر را در هر نسل مدیریت می کند:
- ارزیابی برازندگی هر فرد.
- انتخاب والدین برای تولید مثل.
- اعمال ترکیب (Crossover) برای ایجاد فرزندان جدید.
- اعمال جهش (Mutation) برای حفظ تنوع جمعیت.
- جایگزینی نسل قدیمی با نسل جدید.
همچنین، برای رسم نتایج و نمایش پیشرفت الگوریتم، کد مربوط به رسم نمودارها و ایجاد جدول نهایی را در این بخش اضافه خواهیم کرد.
8. اجرای کامل الگوریتم
در نهایت، باید پارامترهای مورد نیاز برای الگوریتم خود را تنظیم کنیم و آن را اجرا کنیم. این پارامترها شامل اندازه جمعیت، تعداد نسل ها، نرخ ترکیب (Crossover Rate)، نرخ جهش (Mutation Rate)، و سایر مقادیر مرتبط می باشند. پس از تنظیم این مقادیر، الگوریتم آماده اجرا خواهد بود تا بهینه ترین راه حل را پیدا کند.
9. شرط توقف (اختیاری)
در این مثال، تعداد مشخصی نسل برای اجرای الگوریتم خود تعیین کردیم. اما به جای آن می توانستیم یک شرط توقف تعیین کنیم که برنامه را زمانی متوقف کند که به مقدار هدف برازندگی برسیم. این شرط می تواند به صورت زیر تعریف شود:
- اگر برازندگی بالاترین فرد جمعیت به مقدار هدف برسد یا از آن عبور کند، الگوریتم متوقف شود.
- یا اگر بهبود برازندگی در طول تعداد مشخصی نسل متوقف شود، الگوریتم خاتمه یابد.
این رویکرد می تواند کارآمدتر باشد زیرا به جای اجرای تعداد ثابت نسل ها، زمانی متوقف می شود که هدف مورد نظر برآورده شود.
10. اضافه کردن تمام مراحل به همدیگر
11. ارزیابی نتایج
پس از اجرای الگوریتم، از خروجی ها استفاده می کنیم تا عملکرد تابع خود را ارزیابی کنیم.
از جدول خود می بینیم که الگوریتم 20 نسل را کامل کرده است و مقدار برازندگی از یک مقدار منفی نسبتاً بزرگ به مقدار منفی کوچک تر در طول نسل ها افزایش یافته است.
این نشان می دهد که الگوریتم به تدریج راه حل های بهتری تولید کرده است و جمعیت در طول نسل ها به سمت راه حل های مطلوب تر همگرا شده است. این روند مثبت حاکی از عملکرد خوب الگوریتم در بهبود راه حل ها می باشد.

با بررسی نمودار برازندگی، متوجه می شویم که برازندگی در طول زمان بهبود یافته است و در نسل های پایانی تقریباً به یک مقدار ثابت رسیده است. این نشان می دهد که الگوریتم در یافتن راه حل های بهتر موفق بوده است.
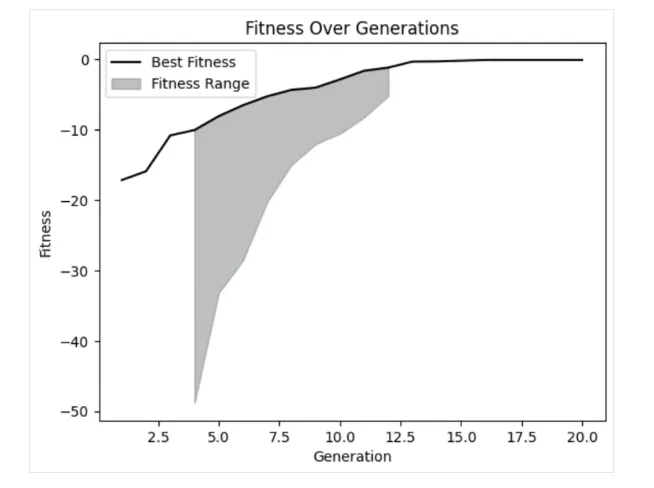
همچنین مشاهده می کنیم که در نسل های اولیه، برخی از راه حل ها بسیار ضعیف بودند که به درستی توسط مدل رد شدند.
نکته دیگر این است که در چند نسل، دامنه تنوع برازندگی محدود بوده است. اگرچه این لزوماً نشانه منفی نیست، اما باید به آن توجه کرد. در برخی موارد، این وضعیت می تواند نشان دهنده “همگرایی زودرس” باشد، مشکلی که به هنگام متنوع نبودن کافی جمعیت رخ می دهد و الگوریتم در یک ناحیه محلی از فضای جستجو گیر کند.
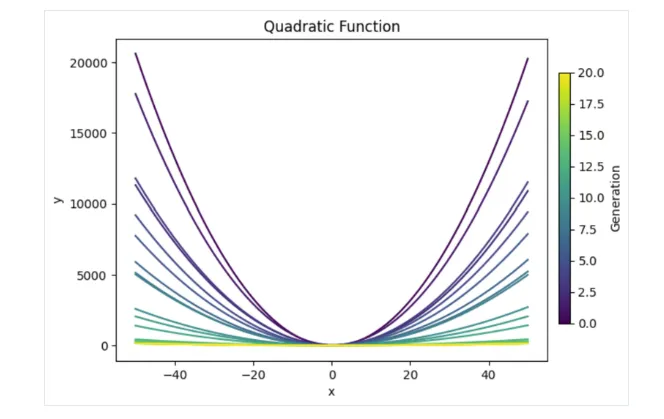
مشاهده می کنیم که راه حل های نسل های اولیه بسیار خمیده هستند، که منطقی است زیرا این معادله یک نمودار به شکل U تولید می کند. اما همان طور که انتظار داشتیم، با پیشرفت نسل ها، منحنی ها به تدریج صاف تر شده اند و این دقیقاً همان چیزی است که هدف ما بود!
نکته مهم:
ما به وضوح فقط در محدوده تعیین شده (-50 تا 50) نتایج را بررسی می کنیم. اگر نمودار را خارج از این محدوده بررسی کنیم، خواهیم دید که حتی این خطوط ظاهراً صاف هنوز هم به شکل U هستند، اما با پایه های وسیع تر.
اهمیت تحلیل محتاطانه:
این مثال نشان می دهد که هنگام تحلیل نتایج باید در فرضیات خود محتاط باشیم و مطمئن شویم که آن ها از پیش بینی های ما پشتیبانی می کنند. مدل ما دقیقاً آنچه را که انتظار داشتیم انجام داده است، اما فقط در محدوده ای که برای آن تعریف کرده بودیم. اگر بخواهیم ترکیبی از مقادیر را پیدا کنیم که شکل صافی در مقیاس بزرگ تر ایجاد کند، باید مدل را با محدوده های وسیع تری اجرا کنیم.
کاربردهای الگوریتم ژنتیک در پایتون
الگوریتم ژنتیک در پایتون کاربردهای متنوعی در زمینه حل مسائل پیچیده و بهینهسازی دارد. برخی از مهمترین کاربردهای آن عبارتند از:
1. بهینه سازی مسائل پیچیده
یکی از کاربردهای اصلی الگوریتم ژنتیک حل مسائل بهینه سازی پیچیده است. این مسائل معمولا شامل فضایی بسیار گسترده از پاسخ ها هستند که جستجو و یافتن راه حل بهینه در آن ها دشوار می باشد. الگوریتم ژنتیک با استفاده از رویکردهای الهام گرفته از تکامل زیستی مانند انتخاب طبیعی، ترکیب و جهش می تواند به تدریج به سمت یافتن پاسخ های بهینه حرکت کند. این روش در مسائلی مانند بهینه سازی ترکیبی، مسیریابی، یا تخصیص منابع بسیار موثر است. به عنوان مثال، در مسئله فروشنده دوره گرد، الگوریتم ژنتیک می تواند بهترین مسیر برای بازدید از شهرها را پیدا کند.
برای پیاده سازی چنین کاربردهایی در پایتون، می توان از کتابخانه هایی مانند PyGAD یا DEAP استفاده کرد. این ابزارها به سادگی اجازه می دهند الگوریتم ژنتیک را برای مسائل خاص تنظیم و پیاده سازی کنید. با تعریف کروموزوم ها و تابع برازندگی مناسب برای مسئله، الگوریتم به صورت خودکار جمعیت را تکامل می دهد تا به جواب نزدیک تر شود. این ویژگی به خصوص برای مسائلی که دارای محدودیت های پیچیده یا غیرخطی هستند، بسیار مفید است.
2. پیدا کردن بهترین ترکیب از ویژگی ها
در یادگیری ماشین، انتخاب ویژگی های مناسب می تواند تأثیر بزرگی روی دقت مدل داشته باشد. الگوریتم ژنتیک می تواند در فرآیند انتخاب ویژگی (Feature Selection) نقش بسیار موثری ایفا کند. این الگوریتم با ارزیابی ترکیب های مختلف از ویژگی ها و شناسایی بهترین ترکیب، می تواند به کاهش ابعاد داده ها و بهبود عملکرد مدل کمک کند. به عنوان مثال، اگر داده ها شامل صدها ویژگی مختلف باشند، الگوریتم ژنتیک می تواند تعیین کند که کدام ترکیب از ویژگی ها برای پیش بینی دقیق تر مناسب تر است.
این فرآیند در پایتون با استفاده از کتابخانه هایی مانند Scikit-learn و PyGAD قابل اجرا است. می توان یک تابع برازندگی تعریف کرد که بر اساس دقت مدل، ترکیب های مختلف ویژگی ها را ارزیابی کند. سپس الگوریتم ژنتیک ترکیب های مختلف را بررسی کرده و بهترین مجموعه را پیشنهاد می دهد. این رویکرد باعث کاهش پیچیدگی محاسباتی و بهبود عملکرد مدل های یادگیری ماشین می شود.
3. حل مسائل ترکیبی
الگوریتم ژنتیک در حل مسائل ترکیبی بسیار کارآمد است، زیرا این مسائل معمولا به تعداد زیادی از ترکیب های ممکن نیاز دارند که با روش های معمول حل کردن آن ها زمان بر و پرهزینه است. این الگوریتم با جستجو در فضای ترکیب ها می تواند به تدریج ترکیب هایی را پیدا کند که بهترین نتایج را ارائه می دهند. به عنوان مثال، در مسئله بسته بندی کوله پشتی، الگوریتم ژنتیک می تواند بهترین ترکیب از اقلام را برای قرار دادن در کوله پشتی انتخاب کند تا ارزش کل حداکثر شود.
در پایتون، این نوع مسائل را می توان با استفاده از الگوریتم ژنتیک و با تعریف یک کروموزوم که نمایانگر یک ترکیب خاص است، حل کرد. با تعریف یک تابع برازندگی که میزان موفقیت هر ترکیب را مشخص می کند، الگوریتم ترکیب های مختلف را ارزیابی کرده و ترکیب بهینه را پیشنهاد می دهد. این روش برای بسیاری از مسائل کاربردی مانند زمان بندی، تخصیص منابع و برنامه ریزی موثر می باشد.
4. طراحی و بهینه سازی شبکه های عصبی
یکی دیگر از کاربردهای جذاب الگوریتم ژنتیک بهینه سازی ساختار شبکه های عصبی است. در طراحی شبکه های عصبی، تعیین ساختار مناسب، مانند تعداد لایه ها، تعداد نورون ها در هر لایه و حتی تنظیمات مربوط به نرخ یادگیری، از اهمیت بالایی برخوردار است. الگوریتم ژنتیک می تواند به صورت خودکار این پارامترها را بهینه سازی کرده و بهترین ساختار شبکه را ارائه دهد. این روش به خصوص در مواردی که تنظیم دستی پارامترها دشوار یا زمان بر است، بسیار مفید است.
در پایتون، این فرآیند با ترکیب الگوریتم ژنتیک و کتابخانه های یادگیری ماشین مانند TensorFlow یا PyTorch قابل اجرا است. با تعریف یک تابع برازندگی که عملکرد شبکه عصبی را بر اساس ساختار و پارامترهای مختلف ارزیابی می کند، الگوریتم ژنتیک می تواند به تدریج پارامترهای بهینه را پیدا کند. این کاربرد در مسائل پیچیده ای مانند پیش بینی، طبقه بندی و حتی شناسایی الگوهای پیچیده مفید می باشد.
5. پیش بینی و شبیه سازی
الگوریتم ژنتیک در پیش بینی و شبیه سازی پدیده های پیچیده نیز کاربرد دارد. در مسائل مربوط به علوم فیزیک، زیست شناسی، اقتصاد و دیگر رشته ها، مدل سازی و پیش بینی دقیق ممکن است دشوار باشد. الگوریتم ژنتیک می تواند به عنوان ابزاری قدرتمند برای یافتن پارامترهای بهینه مدل ها و شبیه سازی نتایج مورد استفاده قرار گیرد. برای مثال، در مدل سازی رشد جمعیت، الگوریتم ژنتیک می تواند مقادیر بهینه برای متغیرهای مختلف را پیدا کرده و پیش بینی های دقیقی ارائه دهد.
در پایتون، این شبیه سازی ها با ترکیب الگوریتم ژنتیک و ابزارهای محاسبات عددی مانند SciPy یا NumPy امکان پذیر است. با تعریف یک تابع برازندگی که میزان دقت پیش بینی را بر اساس مقادیر واقعی ارزیابی می کند، الگوریتم می تواند پارامترهای مناسب را پیدا کرده و مدل را بهینه کند. این روش برای حل مسائل چند متغیره و پیچیده بسیار موثر است.
6. حل مسائل طراحی مهندسی
در طراحی مهندسی، یافتن راه حل های بهینه برای طراحی قطعات یا ساختارها از اهمیت بالایی برخوردار است. الگوریتم ژنتیک می تواند به مهندسان کمک کند تا پارامترهای طراحی را به گونه ای تنظیم کنند که عملکرد بهینه حاصل شود. برای مثال، در طراحی هواپیما، الگوریتم ژنتیک می تواند بهینه ترین شکل بال ها را برای کاهش مقاومت هوا پیدا کند. همچنین در تحلیل ساختارهای پیچیده، این الگوریتم می تواند طراحی هایی ارائه دهد که هم از نظر وزن و هم از نظر استحکام بهینه باشند.
در پایتون، این مسائل را می توان با تعریف کروموزوم هایی که نمایانگر پارامترهای طراحی هستند و یک تابع برازندگی که معیارهای طراحی را ارزیابی می کند، حل کرد. ابزارهایی مانند PyGAD و CAD-based optimizers می توانند برای مسائل طراحی مهندسی به کار گرفته شوند. این روش در صنایعی مانند خودروسازی، هوافضا و مهندسی عمران کاربرد گسترده دارد.
7. حل مسائل بازی های استراتژیک
الگوریتم ژنتیک می تواند برای پیدا کردن بهترین استراتژی در بازی های استراتژیک یا ایجاد برنامه های هوش مصنوعی استفاده شود. این کاربرد به خصوص در بازی هایی که نیاز به تصمیم گیری های پیچیده دارند، مانند شطرنج، بسیار موثر است. الگوریتم ژنتیک می تواند استراتژی های مختلف را ارزیابی کرده و با ترکیب و بهینه سازی آن ها، بهترین رویکرد را ارائه دهد. این روش می تواند به بهبود عملکرد بازیکن های هوش مصنوعی کمک کند.
در پایتون، با استفاده از الگوریتم ژنتیک می توان استراتژی های مختلف را به صورت کروموزوم تعریف کرد و سپس آن ها را بر اساس برازندگی ارزیابی نمود. برای مثال، یک تابع برازندگی می تواند تعداد پیروزی ها یا عملکرد بازیکن را ارزیابی کند. این کاربرد در طراحی بازی های هوشمند و همچنین آموزش مدل های تقویتی بسیار مفید است.
8. تولید محتوای خلاقانه
الگوریتم ژنتیک حتی در تولید محتوای خلاقانه مانند آثار هنری و موسیقی نیز کاربرد دارد. این الگوریتم می تواند برای ترکیب یا ایجاد قطعات جدید استفاده شود. برای مثال، با تعریف معیارهایی مانند هماهنگی، ریتم یا زیبایی شناسی، الگوریتم ژنتیک می تواند به تولید موسیقی های جدید یا طراحی آثار هنری کمک کند. این کاربرد در زمینه های سرگرمی و هنر دیجیتال محبوبیت زیادی دارد.
در پایتون، این فرآیند با استفاده از الگوریتم ژنتیک و ابزارهای مرتبط با هنر و موسیقی قابل اجرا است. می توان قطعات موسیقی را به صورت داده های عددی نمایش داد و با ترکیب یا جهش آن ها، قطعات جدید تولید کرد. ابزارهایی مانند Music21 یا الگوریتم های سفارشی می توانند برای این نوع تولیدات خلاقانه به کار گرفته شوند.





سئو ادیتور2025-12-19T01:08:03+03:30دسامبر 19, 2025|بدون ديدگاه
چکیده مقاله: سئو کلاه خاکستری یکی از تکنیک های بهینه سازی موتور جستجو است که میان سئو کلاه سفید و سئو کلاه سیاه قرار می گیرد. این روش ها معمولاً به استفاده از شیوه [...]

سئو ادیتور2025-12-05T21:34:41+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: در سال ۲۰۲۵ بحث سئو کلاه سیاه دوباره به عنوان يک موضوع جنجالی در حوزه بهينه سازی موتورهای جستجو مطرح شده است. با توجه به به روزرسانی های پي در پی الگوريتم [...]

سئو ادیتور2025-12-05T21:41:27+03:30دسامبر 5, 2025|بدون ديدگاه
چکیده مقاله: بهینه سازی هوش مصنوعی یا AIO به عنوان یکی از پیشرفته ترین رویکردهای دنیای فناوری امروز، بر افزایش کارایی، دقت و سرعت سیستم های هوشمند تمرکز دارد. این مفهوم تنها به بهبود [...]

مدیر2025-12-04T00:29:49+03:30دسامبر 4, 2025|بدون ديدگاه
چکیده مقاله: پرپلکسیتی یک موتور جستجوی هوش مصنوعی است که تلاش می کند جستجو در وب را به شکل هوشمند و پاسخ محور ارائه دهد. این ابزار به جای نمایش فهرست طولانی از لینک [...]

مدیر2025-12-01T00:45:09+03:30دسامبر 1, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های ChatGPT نسل مدل های ChatGPT از نسخه هاي ساده تر مانند GPT-3.5 تا خانواده هاي قدرتمندتر GPT-4 و نسخه هاي بهینه شده آن مانند GPT-4 Turbo و GPT-4o تکامل [...]

مدیر2025-11-28T23:50:42+03:30نوامبر 28, 2025|بدون ديدگاه
چکیده مقاله: انواع مدل های Gemini در سال های اخير به عنوان يکي از پيشرفته ترين خانواده هاي مدل هاي هوش مصنوعي معرفي شده اند و توانسته اند در زمينه هاي مختلف از جمله [...]